本文介绍Python中的字典与集合的使用,代码中若有人名只是练习随意打的代码,没有任何其他意图。
1. 字典的初识
【1】字典的创建与价值
字典(Dictionary)是一种在Python中用于存储和组织数据的数据结构。元素由键和对应的值组成。其中,键(Key)必须是唯一的,而值(Value)则可以是任意类型的数据。在 Python 中,字典使用大括 {}来表示,键和值之间使用冒:进行分隔,多个键值对之间使用逗,分隔。
# 列表
info_list = ["yuan", 18, 185, 70]
# 字典
info_dict = {"name": "yuan", "age": 18, "height": 185, "weight": 70}
print(type(info_dict)) # <class 'dict'>字典类型很像学生时代常用的新华字典。我们知道,通过新华字典中的音节表,可以快速找到想要查找的汉字。其中,字典里的音节表就相当于字典类型中的键,而键对应的汉字则相当于值。

字典的灵魂:
字典是由一个一个的 key-value 构成的,字典通过键而不是通过索引来管理元素。字典的操作都是通过 key 来完成的。
【2】字典的存储与特点
hash:百度百科
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
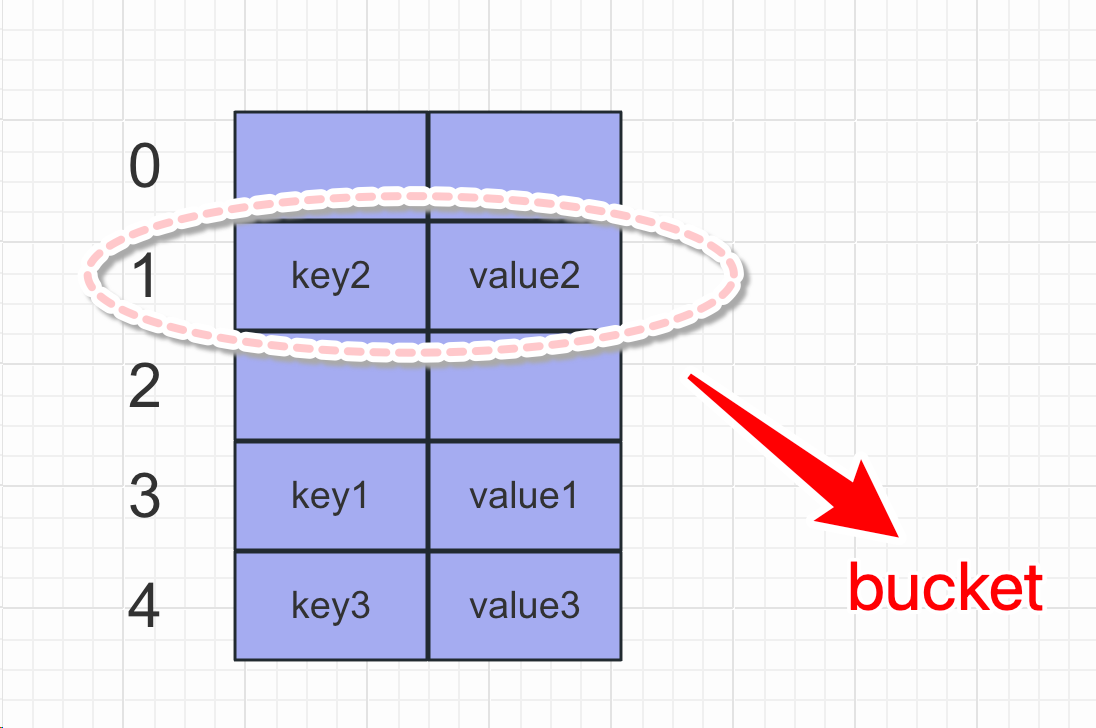
将一对键值放入字典的过程:(和列表一样,底层也是数组,但是字典使用的没有索引一说,只用键操作)
先定义一个字典,再写入值
d = {}
d["name"] = "yuan"在执行第二行时,第一步就是计算"name"的散列值,python中可以用hash函数得到hash值,再将得到的值放入bin函数,返回int类型的二进制。
print(bin(hash("name")))假设输出结果是:-0b100000111110010100000010010010010101100010000011001000011010
假设数组长度为10,我们取出计算出的散列值,最右边3位数作为偏移量,即010,十进制是数字2,我们查看偏移量为2对应的bucket的位置是否为空,如果为空,则将键值放进去,如果不为空,依次取右边3位作为偏移量011,十进制是数字3,再查看偏移量3的bucket是否为空,直到单元为空的bucket将键值放进去。以上就是字典的存储原理
注意:如果key已经存在的情况下,会更新值!
当进行字典的查询时:
d["name"]
d.get("name") 第一步与存储一样,先计算键的散列值,取出后三位010,十进制为2的偏移量,找到对应的bucket的位置,查看是否为空,如果为空就返回None,不为空就获取键并计算键的散列值,计算后将刚计算的散列值与要查询的键的散列值比较,相同就返回对应bucket位置的value,不同就往前再取三位重新计算偏移量,依次取完后还是没有结果就返回None。
print(bin(hash("name")))每次执行结果不同:这是因为 Python 在每次启动时,使用的哈希种子(hash seed)是随机选择的。哈希种子的随机选择是为了增加哈希函数的安全性和防止潜在的哈希碰撞攻击。
字典的特点:
无序性:字典中的元素没有特定的顺序,不像列表和元组那样按照索引访问。通过键来访问和操作字典中的值。
键是唯一的且不可变类型对象,用于标识值。值可以是任意类型的对象,如整数、字符串、列表、元组等。
可变性:可以向字典中添加、修改和删除键值对。这使得字典成为存储和操作动态数据的理想选择。
这里要注意的是Python中的字典与Java中的HashMap的数据结构还是区别较大的!
Python 官方在 3.7 版本中明确将 字典保持插入顺序 纳入语言规范(官方文档),从此成为可靠行为。
问题:
1、顺序是如何实现的?可能是底层往数组插入bucket时有个地方记录了顺序!所以,3.7版本后其实都是有序字典!
2、key为什么一定要是不可变的?或者说hash函数为什么一定是不可变对象?Java中的hash函数也是么?
不可变是因为,如果key是可变对象,对象变化后会导致无法根据这个key再找到对应的值,自定义对象可以通过重写__eq__和__hash__实现不可变,这本质上和Java是相同的,只不过Java中的HashMap允许将不可变对象作为key,但是对象变化后就无法找到对应的值了,而python中如果key是可变对象会直接报错!
但要注意的是这里讨论的是hash算法,但是Python中的字典和Java中的HashMap整体在底层数据结构实现是有很大不同的!
2. 字典的基本操作
# 使用 { } 创建字典
gf = {"name":"高圆圆","age":32}
# 无序(只是强调不能用索引),属于容器类型
print(len(gf))
# (1) 查键值
print(gf["name"]) # 高圆圆
print(gf["age"]) # 32
# print(gf["names"]) # 键不存在会报错,可以与in操作符一起使用避免报错
print(gf.get("names")) # 使用内置方法。这个不报错
# (2) 添加或修改键值对,注意:如果键存在,则是修改,否则是添加
gf["age"] = 29 # 修改键的值
gf["gender"] = "female" # 添加键值对
# (3) 删除键值对 del 删除命令
print(gf)
del gf["age"]
print(gf)
# del gf
# print(gf)
# (4) 判断键是否存在某字典中
print("weight" in gf)
# (5) 循环:注意默认迭代返回的是key
for key in gf:
print(key,gf[key])
# enumerate() 只是添加一个计数器,不影响字典本身的迭代顺序
for index, key in enumerate(gf):
print(index, key)
for (key, value) in gf.items():
print(key,value)
Python 字典中键(key)的名字不能被修改,我们只能根据键(key)修改值(value)。
3. 字典的内置方法

gf = {"name": "高圆圆", "age": 32}
# (1) 创建字典
knowledge = ['语文', '数学', '英语']
scores = dict.fromkeys(knowledge, 60)
print(scores)
# (2) 获取某键的值,键不存在返回None
print(gf.get("name")) # "高圆圆
print(gf.get("a", 666)) # 可以提供默认值
# (3) 更新键值:添加或更改(无返回值)
gf.update({"age": 18, "weight": "50kg"})
print(gf) # {'name': '高圆圆', 'age': 18, 'weight': '50kg'}
# (4) 删除weight键值对
ret = gf.pop("weight") # 返回删除的值
ret = gf.pop("weight1", "1") # 返回删除的值,提供默认值可以不报错
print(gf)
# (5) 遍历字典键值对,k, v不需要加括号,本质上元组,但加括号多余,见下面的补充说明中的本质原因
for k, v in gf.items():
print(k, v)
# 补充
# 遍历字典更多用items()返回元组!
# 字典也可以深浅拷贝,可以问AI
# 字典的in判断key是in直接字典,不需要转keys!
"s" in {"s": "a"} 4. 可变数据类型之字典
# 列表字典存储方式
l =[1,2,3]
d = {"a": 1, "b": 2}
# 案例1:
l1 = [3, 4, 5]
d1 = {"a": 1, "b": 2, "c": l1}
l1.append(6)
print(d1)
d1["c"][0] = 300
print(l1)
# 案例2:
d2 = {"x": 10, "y": 20}
d3 = {"a": 1, "b": 2, "c": d2}
d2["z"] = 30
# d3["c"].update({"z": 30})
print(d3)
# d3["c"]["x"] = 100
d3["c"].update({"x": 100})
print(d2)
d3["c"] = 3
# 案例3:
d4 = {"x": 10, "y": 20}
l2 = [1, 2, d4]
# d4["z"] = 30
# print(l2)
l2[2].pop("y")
print(d4)5. 列表字典嵌套实战案例
【1】基于字典的客户信息管理系统
1.列表嵌套字典版本
# 初始化客户信息列表
customers = [
{
"name": "Alice",
"age": 25,
"email": "alice@example.com"
},
{
"name": "Bob",
"age": 28,
"email": "bob@example.com"
},
]
while True:
print("""
1. 添加客户
2. 删除客户
3. 修改客户
4. 查询一个客户
5. 查询所有客户
6. 退出
""")
choice = input("请输入您的选择:")
if choice == "1":
# (1) 添加客户
name = input("请输入添加客户的姓名:")
age = int(input("请输入添加客户的年龄:"))
email = input("请输入添加客户的邮箱:")
new_customer = {
"name": name,
"age": age,
"email": email
}
customers.append(new_customer)
print(f"添加客户{name}成功!")
print(f"当前客户列表:{customers}")
elif choice == "2":
# (2) 删除用户
del_customer_name = input("请输入要删除客户的姓名:")
flag = False
for customerD in customers:
if customerD["name"] == del_customer_name:
customers.remove(customerD)
print(f"客户{del_customer_name}删除成功!")
flag = True
break
if flag:
print(f"当前客户列表:{customers}")
else:
print(f"客户{del_customer_name}不存在!")
elif choice == "3":
# (3) 修改客户
update_customer_name = input("请输入修改客户的姓名:")
name = input("请输入修改客户的新姓名:")
age = int(input("请输入修改客户的新年龄:"))
email = input("请输入修改客户的新邮箱:")
for customerD in customers:
if customerD["name"] == update_customer_name:
customerD.update({"name": name, "age": age, "email": email})
break
print(f"当前用户列表: {customers}")
elif choice == "4":
# (4) 查询某一个客户
query_customer_name = input("请输入查看客户的姓名:")
for customerD in customers:
if customerD["name"] == query_customer_name:
# 这时要注意下单引双引的问题,不要误认为f-string里面不能有括号字符!
print(f"姓名:{customerD.get('name')},年龄: {customerD.get('age')},邮箱:{customerD.get('email')}")
break
elif choice == "5":
# (5) 遍历每一个一个客户信息
if customers:
for customerD in customers:
print(f"姓名:{customerD.get('name'):10},年龄:{customerD.get('age')},邮箱:{customerD.get('email')}")
elif choice == "6":
print("退出程序!")
break
else:
print("非法输入!")
# 补充:多加一个逗号就是隐藏元组了,Python与JavaScript不一样!!!!
new_customer = {
"name": "danny",
"age": 35,
"email": "123"
},
print(new_customer)
print(type(new_customer))2.字典嵌套字典版本
# 初始化客户信息列表
customers = {
1001: {
"name": "Alice",
"age": 25,
"email": "alice@example.com"
},
1002: {
"name": "Bob",
"age": 28,
"email": "bob@example.com"
},
}
while True:
print("""
1. 添加客户
2. 删除客户
3. 修改客户
4. 查询一个客户
5. 查询所有客户
6. 退出
""")
choice = input("请输入您的选择:")
if choice == "1":
# (1) 添加客户
id = int(input("请输入添加客户的ID:"))
if id in customers: # "1001" in {1001:...}
print("该ID已经存在!")
else:
name = input("请输入添加客户的姓名:")
age = int(input("请输入添加客户的年龄:"))
email = input("请输入添加客户的邮箱:")
new_customer = {
"name": name,
"age": age,
"email": email
}
customers.update({id: new_customer})
print(f"添加客户{name}成功!")
print(f"当前客户:{customers}")
elif choice == "2":
# (2) 删除用户
del_customer_id = int(input("请输入删除客户的ID:"))
if del_customer_id in customers:
customers.pop(del_customer_id)
print(f"删除{del_customer_id}客户成功!")
print("当前客户:", customers)
else:
print("该ID不存在!")
elif choice == "3":
# (3) 修改客户
update_customer_id = int(input("请输入修改客户的ID:"))
if update_customer_id in customers:
name = input("请输入修改客户新的姓名:")
age = input("请输入修改客户新的年龄:")
email = input("请输入修改客户新的邮箱:")
# 方式1:
# customers[update_customer_id]["name"] = name
# customers[update_customer_id]["age"] = age
# customers[update_customer_id]["email"] = email
# 方式2:
customers[update_customer_id].update({"name": name, "age": age, "email": email})
# 方式3:
# customers[update_customer_id] = {
# "name": name,
# "age": age,
# "email": email,
# }
print(f"{update_customer_id}客户修改成功!")
print("当前客户:", customers)
else:
print("该ID不存在!")
elif choice == "4":
# (4) 查询某一个客户
query_customer_id = int(input("请输入查看客户的ID:"))
if query_customer_id in customers:
customerD = customers[query_customer_id]
print(f"姓名:{customerD.get('name')},年龄:{customerD.get('age')},邮箱:{customerD.get('email')}")
else:
print("该客户ID不存在!")
elif choice == "5":
# (5) 遍历每一个一个客户信息
if customers:
for key,customerDict in customers.items():
print(f"客户ID:{key},姓名:{customerDict.get('name'):10},年龄:{customerDict.get('age')},邮箱:{customerDict.get('email')}")
else:
print("当前没有任何客户信息!")
elif choice == "6":
print("退出程序!")
break
else:
print("非法输入!")
【2】天气预报数据解析
# 注册地址:http://www.tianqiapi.com/
# API接口v91:https://v1.yiketianqi.com/api?unescape=1&version=v91&appid=[填写你的appid]&appsecret=[填写你的密钥]&ext=&cityid=&city=
import requests
url = "https://v1.yiketianqi.com/api?unescape=1&version=v91&appid==[填写你的appid]&appsecret=[填写你的密钥]&ext=&cityid=&city="
response = requests.get(url)
data = response.json()
data_list = data.get("data")
for i in data_list:
print(f"{i.get('date')},天气状况: {i.get('wea')},平均温{i.get('tem')}")6. 集合
集合(Set)是Python中的一种无序、不重复的数据结构。集合是由一组元素组成的,这些元素必须是不可变数据类型,但在集合中每个元素都是唯一的,即集合中不存在重复的元素。
集合的基本语法和特性:
s1 = {1,2,3}
print(len(s1))
print(type(s1))
# 元素值必须是不可变数据类型
# s1 = {1, 2, 3,[4,5]} # 报错
# (1) 无序:没有索引
# print(s1[0])
# (2) 唯一: 集合可以去重
s2 = {1, 2, 3, 3, 2, 2}
print(s2)
# 面试题(去重):
l = [1, 2, 3, 3, 2, 2]
# 类型转换:将列表转为set
print(set(l)) # {1, 2, 3}
print(list(set(l))) # [1, 2, 3]1. 无序性:集合中的元素是无序的,即元素没有固定的顺序。因此,不能使用索引来访问集合中的元素。
2. 唯一性:集合中的元素是唯一的,不允许存在重复的元素。如果尝试向集合中添加已经存在的元素,集合不会发生变化。
3. 可变性:集合是可变的,可以通过添加或删除元素来改变集合的内容。
集合的内置方法:
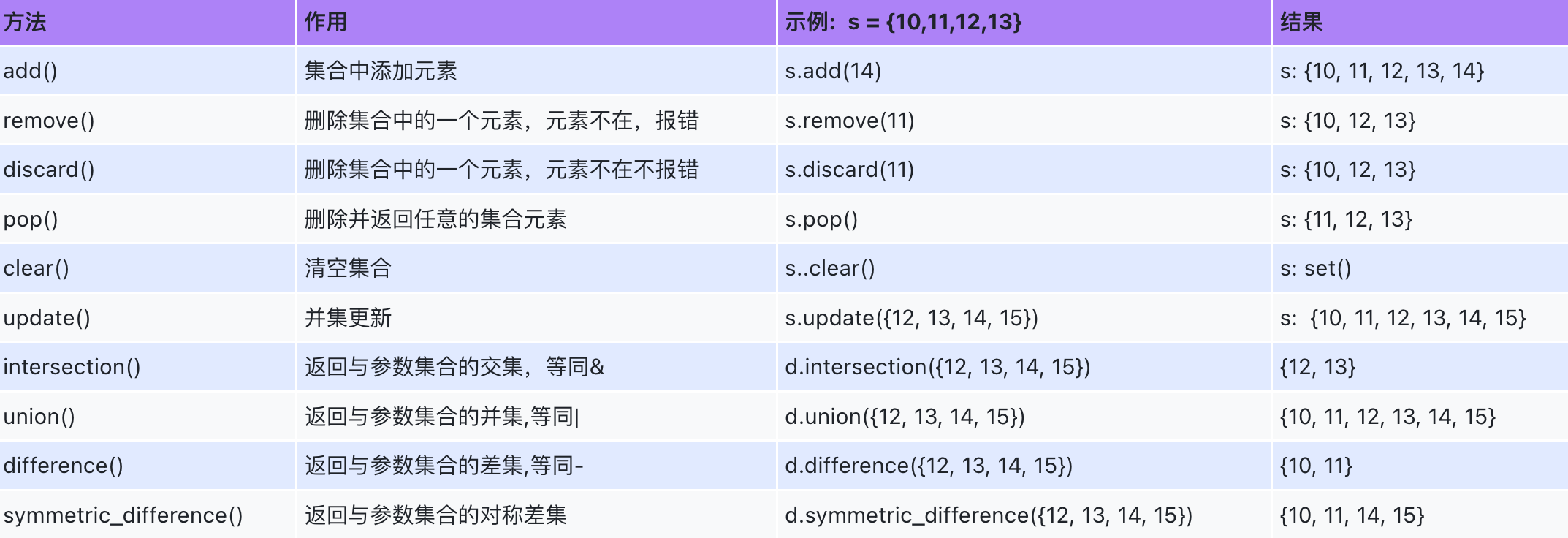
s3 = {1, 2, 3}
# 增删改查
# 增
s3.add(4)
s3.add(3)
print(s3)
s3.update({3, 4, 5})
print(s3)
# l = [1, 2, 3]
# l.extend([3, 4, 5])
# print(l)
# 删
s3.remove(2)
# s3.remove(222) # 不存在报错!
s3.discard(2)
s3.discard(222)
s3.pop()
s3.clear()
print(s3) # set()
# 方式1: 操作符 交集(&) 差集(-) 并集(|),注意:会计算出新的集合,并不会影响原集合
s1 = {1, 2, 3, 4}
s2 = {3, 4, 5, 6}
print(s1 & s2) # {3, 4}
print(s2 & s1) # {3, 4}
print(s1 - s2) # {1, 2}
print(s2 - s1) # {5, 6}
print(s1 | s2) # {1, 2, 3, 4, 5, 6}
print(s2 | s1) # {1, 2, 3, 4, 5, 6}
print(s1, s2)
# 方式2:集合的内置方法
s1 = {1, 2, 3, 4}
s2 = {3, 4, 5, 6}
# 交集
print(s1.intersection(s2)) # {3, 4}
print(s2.intersection(s1)) # {3, 4}
# 差集
print(s1.difference(s2)) # {1, 2}
print(s2.difference(s1)) # {5, 6}
print(s1.symmetric_difference(s2)) # {1, 2, 5, 6}
print(s2.symmetric_difference(s1)) # {1, 2, 5, 6}
# 并集
print(s1.union(s2)) # {1, 2, 3, 4, 5, 6}
print(s2.union(s1)) # {1, 2, 3, 4, 5, 6}商品推荐系统案例:
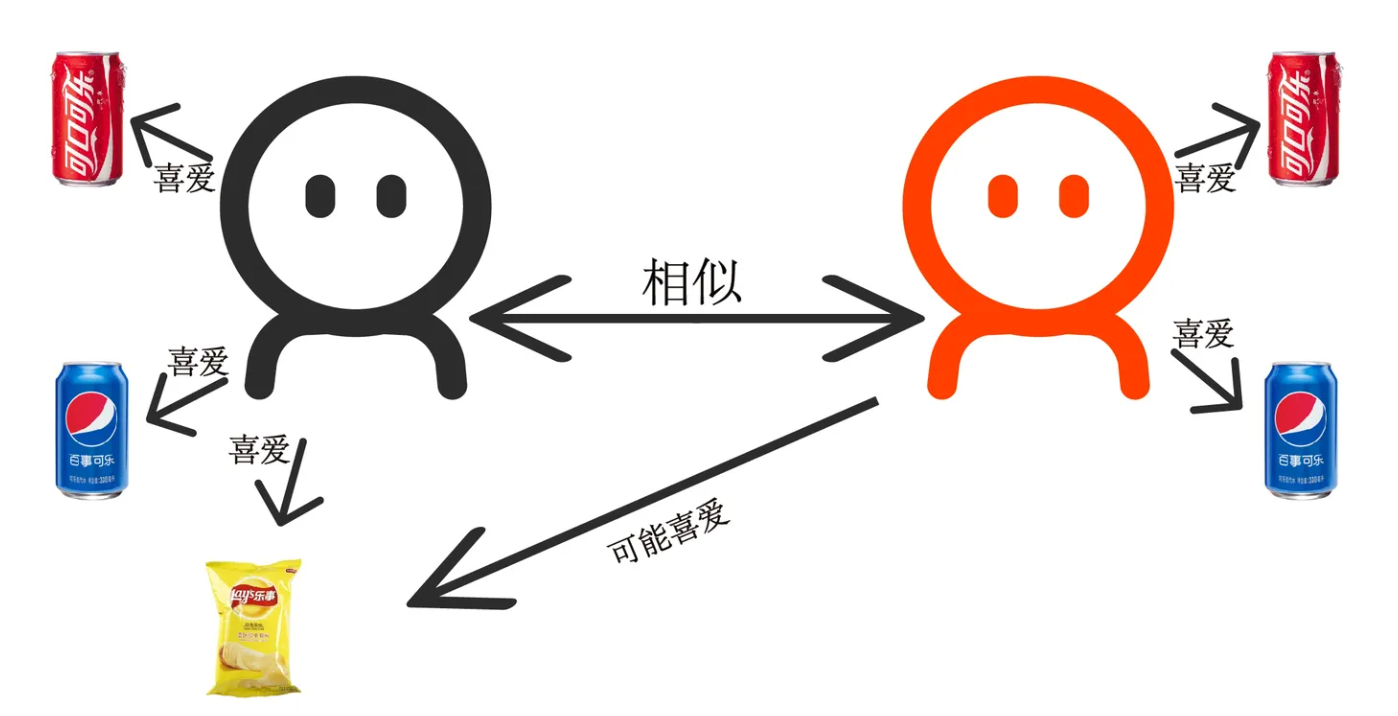
peiQi_hobby = {"螺狮粉", "臭豆腐", "榴莲", "apple"}
alex_hobby = {"螺狮粉", "臭豆腐", "榴莲", "💩", 'pizza'}
yuan_hobby = {"pizza", "salad", "ice cream", "臭豆腐", "榴莲", }
hobbies = [peiQi_hobby, yuan_hobby, alex_hobby]
# 给peiQi推荐商品:
# 思路:A与B喜好取交集,如果交集数量大于某个值,代表两人相似,再求互相求差集,差集的结果就是推荐的商品!
# 版本1:
hobbies.remove(peiQi_hobby)
peiQi_list = []
for hobby in hobbies:
if len(peiQi_hobby.intersection(hobby)) >= 2:
# print(list(hobby - peiQi_hobby))
peiQi_list.extend(list(hobby - peiQi_hobby))
print(list(set(peiQi_list)))
peiQi_hobby = {"螺狮粉", "臭豆腐", "榴莲", "apple"}
alex_hobby = {"螺狮粉", "臭豆腐", "榴莲", "💩", 'pizza'}
yuan_hobby = {"pizza", "salad", "ice cream", "臭豆腐", "榴莲", }
hobbies = [peiQi_hobby, yuan_hobby, alex_hobby]
# 版本2:
hobbies.remove(peiQi_hobby)
# peiQi_set = {}
# print(type(peiQi_set)) # 这个声明是字典,集合初始化要使用内置方法!!!
peiQi_set = set()
for hobby in hobbies:
if len(peiQi_hobby.intersection(hobby)) >= 2:
# print(hobby - peiQi_hobby)
peiQi_set.update(hobby - peiQi_hobby)
print(list(peiQi_set))7. 今日作业
给定两个字典,找到它们共有的键存放到一个列表中
dict1 = {'A': 1, 'B': 2, 'C': 3, 'D': 4}
dict2 = {'B': 20, 'D': 40, 'E': 50}
print(set(dict1.keys()) & set(dict2.keys()))
# 课堂解法
dict1 = {'A': 1, 'B': 2, 'C': 3, 'D': 4}
dict2 = {'B': 20, 'D': 40, 'E': 50}
unique_keys = []
for key in dict1:
if key in dict2:
unique_keys.append(key)
print(unique_keys)2.给定一个字典,找到字典中值最大的键:my_dict = {'A': 10, 'B': 5, 'C': 15, 'D': 20}
max_key = None
max_value = 0
my_dict = {'A': 10, 'B': 5, 'C': 15, 'D': 20}
for key, val in my_dict.items():
if val > max_value:
max_key = key
print(max_key)3.字典值的乘积:编写一个程序,计算给定字典中所有值的乘积:my_dict = {'A': 2, 'B': 3, 'C': 4, 'D': 5}
my_dict = {'A': 2, 'B': 3, 'C': 4, 'D': 5}
val_list = my_dict.values()
ret = 1
for val in val_list:
ret *= val
print(ret)4.编写一个程序,统计给定列表中每个元素出现的次数,并将结果存储在一个字典中。
my_list = [1, 2, 3, 2, 1, 3, 4, 5, 2, 1]
# keys = set(my_list)
count_mapping = dict.fromkeys(my_list, 0)
for i in my_list:
count_mapping[i] += 1
print(count_mapping)
5.编写一个程序,将两个字典合并,并将相同键对应的值进行加法运算。
dict1 = {'A': 1, 'B': 2, 'C': 3}
dict2 = {'B': 10, 'D': 20, 'C': 30}
merge_dict = dict1.copy()
for k, v in dict2.items():
if k in merge_dict:
merge_dict[k] += v
else:
merge_dict[k] = v
print(merge_dict)
6.对列表元素先去重再排序l = [1, 12, 1, 2, 2, 3, 5]
l = [1, 12, 1, 2, 2, 3, 5]
new_l = list(set(l))
# new_l.sort()
new_l.sort(reverse=True)
print(new_l)7.假设有一个班级的学生成绩数据,数据结构如下:
students = [
{"name": "Alice", "score": 85},
{"name": "Bob", "score": 76},
{"name": "Charlie", "score": 90},
{"name": "David", "score": 68},
]请编写程序完成以下操作:
计算学生人数。
计算班级总分和平均分。
找出成绩最高和最低的学生。
students = [
{"name": "Alice", "score": 85},
{"name": "Bob", "score": 76},
{"name": "Charlie", "score": 90},
{"name": "David", "score": 68},
{"name": "Eva", "score": 92}
]
count = len(students)
print(f"班级人数: {count}")
sum = 0
for student in students:
sum += student["score"]
print(f"班级部分: {sum}")
print(f"班级平均分: {sum / count:.2f}") # 格式化复习下
max_key = None
max_val = 0
min_key = None
min_val = 0
for student in students:
if not max_key or student["score"] > max_val:
max_key = student["name"]
max_val = student["score"]
if not min_key or student["score"] < min_val:
min_key = student["name"]
min_val = student["score"]
print(f"分数最高的学生: {max_key},分数为: {max_val}")
print(f"分数最低的学生: {min_key},分数为: {min_val}")8.假设有一个嵌套字典,表示学生的成绩数据,数据结构如下:
students = {
"Alice": {"math": 85, "english": 90, "history": 78},
"Bob": {"math": 76, "english": 82, "history": 88},
"Charlie": {"math": 90, "english": 92, "history": 86},
"David": {"math": 68, "english": 72, "history": 80},
"Eva": {"math": 92, "english": 88, "history": 90}
}请编写程序完成以下操作:
打印每个学生的姓名和总分。
打印每个学生的平均分。
students = {
"Alice": {"math": 85, "english": 90, "history": 78},
"Bob": {"math": 76, "english": 82, "history": 88},
"Charlie": {"math": 90, "english": 92, "history": 86},
"David": {"math": 68, "english": 72, "history": 80},
"Eva": {"math": 92, "english": 88, "history": 90}
}
for student_name,socre_dict in students.items():
student_sum = 0
for socre in socre_dict.values():
student_sum += socre
print(f"姓名: {student_name}\t总分: {student_sum}\t平均分: {student_sum / len(socre_dict):.2f}")9.配置字典中的查询操作:更新config中服务器的端口为8090,日志级别更新为DEBUG
config = {
"数据库": {
"主机": "localhost",
"端口": 3306,
"用户名": "admin",
"密码": "password"
},
"服务器": {
"IP地址": "192.168.0.1",
"端口": 8080,
"日志级别": "INFO"
},
# ...
}config = {
"数据库": {
"主机": "localhost",
"端口": 3306,
"用户名": "admin",
"密码": "password"
},
"服务器": {
"IP地址": "192.168.0.1",
"端口": 8080,
"日志级别": "INFO"
},
# ...
}
sever_config = config.get("服务器")
if sever_config:
sever_config.update({"端口": 8090, "日志级别": "DEBUG"})
print(config)10.基于以下数据结构实现一个购物车系统,可以添加商品到购物车,删除商品,打印当前购物车所有商品以及总价
shopping_cart = [
{
"name": "mac电脑",
"price": 14999,
"quantity": 1
},
{
"name": "iphone15",
"price": 9980,
"quantity": 1
}
]shopping_cart = [
{
"name": "mac电脑",
"price": 14999,
"quantity": 1
},
{
"name": "iphone15",
"price": 9980,
"quantity": 1
}
]
while True:
print("===========购物车=============")
print("请选择商品")
print("1.添加商品")
print("2.删除商品")
print("3.查询购物车")
print("4.退出")
choice = input("请输入选项")
if choice == "1":
# print("添加商品")
name = input("请输入商品名称")
price = float(input("请输入商品价格"))
quantity = int(input("请输入商品数量"))
item = {
"name": name,
"price": price,
"quantity": quantity
}
shopping_cart.append(item)
elif choice == "2":
print("删除商品")
num = int(input("请输入商品的序号"))
index = num - 1
# todo 判断索引越界
del_goods = shopping_cart.pop(index)
print(f"商品: {del_goods.get('name')}删除成功!")
elif choice == "3":
print("=" * 30)
total = 0.0
print("当前商品: ")
for i, goods in enumerate(shopping_cart):
print(f"{i + 1}. {goods.get('name')}\t价格: {goods.get('price')}\t数量: {goods.get('quantity')}")
total += goods.get('price') * goods.get('quantity')
print("总金额: ", total)
print("=" * 30)
elif choice == "4":
print("程序退出!")
break
else:
print("非法输入!")