1. 字符编码
计算机存储信息的大小,最基本的单位是字节。
KB=1024B
1MB=1024KB
1GB=1024MB
1TB=1024GB
字符编码是将字符集中的字符映射到二进制表示形式的规则集。ASCII、GBK、Unicode和UTF-8是常见的字符编码标准。下面我将对每种编码进行简要介绍:
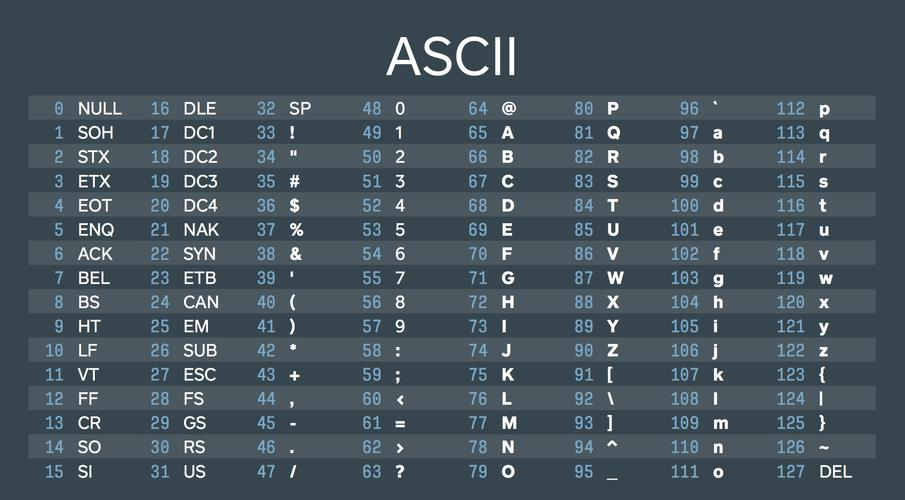
1. ASCII(American Standard Code for Information Interchange):ASCII 是最早的字符编码标准,使用 7 位二进制数(0-127)表示 128 个常用字符,包括英文字母、数字和一些常见的符号。ASCII 编码是单字节编码,每个字符占用一个字节的存储空间。
2. GBK(GuoBiao/Kuòbiāo):GBK 是中文编码标准,是国家标准 GB 2312 的扩展,支持汉字字符。GBK 使用双字节编码,其中一个字节表示高位,另一个字节表示低位,可以表示大约 21000 个汉字和其他字符。GBK 编码兼容 ASCII 编码,即 ASCII 字符可以用一个字节表示。
3. Unicode(统一码):Unicode 是一种字符编码标准,旨在为全球所有的字符提供唯一的标识符。它使用固定长度的编码单元表示字符,最常见的编码单元是 16 位(如 UTF-16)。Unicode 可以表示几乎所有语言的字符。
4. UTF-8(Unicode Transformation Format-8):UTF-8 是一种可变长度的 Unicode 编码标准,通过使用不同长度的字节序列来表示字符。UTF-8 是互联网上最常用的字符编码标准,因为它兼容 ASCII 编码,可以表示全球各种语言的字符。它使用 8 位字节编码,根据字符的不同范围使用不同长度的字节,ASCII 字符使用一个字节表示,而其他字符使用多个字节表示。
编码和解码是在字符编码过程中使用的两个关键概念。编码是将字符转换为特定编码标准下的二进制表示形式,而解码则是将二进制数据转换回字符形式。
在字符编码中,编码器用于将字符转换为相应编码标准下的二进制数据,而解码器用于将二进制数据转换回字符形式。编码和解码的过程是互逆的,可以通过相应的编码和解码算法进行转换。
text = "Hello, 你好"
# 编码过程
encoded = text.encode('utf-8') # 使用 UTF-8 编码将文本转换为二进制数据
print("编码后的数据:", encoded)
# 解码过程
decoded = encoded.decode('utf-8') # 使用 UTF-8 解码将二进制数据转换为文本
print("解码后的文本:", decoded)需要注意的是,在编码和解码过程中,要确保使用相同的编码标准进行处理。否则,编码和解码的结果可能会不正确,导致乱码或数据损坏。
2. 文件操作
在 Python 中,如果想要操作文件,首先需要创建或者打开指定的文件,并创建一个文件对象,而这些工作可以通过内置的 open() 函数实现。
open() 函数用于创建或打开指定文件,该函数的常用语法格式如下:
def open(file, mode='r', encoding=None,): # known special case of open【1】读文件
file = open("example.txt", "r", encoding="utf-8") # 以只读模式打开文件
# content = file.read() # 读取整个文件内容
# print(content)
# line = file.readline() # 读取一行内容
# print(line)
lines = file.readlines() # 读取所有行,并返回列表
print(lines)
file.close() # 关闭
# 这个地方要注意下,文件指针在读取过程中会自动移动,因此不能重复读取相同的内容example.txt就是一个普通的记事本,内容如下:
第1行内容
第2行内容
第3行内容【2】写文件
file = open("example2.txt", "w") # 以只写模式打开文件
file.write("Hello, World!") # 向文件写入内容
# Python 的文件对象中,不仅提供了 write() 函数,还提供了 writelines() 函数,可以实现将字符串列表写入文件中。
# file.writelines(f.readlines())
file.close() # 关闭注意,写入函数只有 write() 和 writelines() 函数,而没有名为 writeline 的函数。
【3】with open
任何一门编程语言中,文件的输入输出、数据库的连接断开等,都是很常见的资源管理操作。但资源都是有限的,在写程序时,必须保证这些资源在使用过后得到释放,不然就容易造成资源泄露,轻者使得系统处理缓慢,严重时会使系统崩溃。
例如,前面在介绍文件操作时,一直强调打开的文件最后一定要关闭,否则会程序的运行造成意想不到的隐患。但是,即便使用 close() 做好了关闭文件的操作,如果在打开文件或文件操作过程中抛出了异常,还是无法及时关闭文件。
为了更好地避免此类问题,不同的编程语言都引入了不同的机制。在Python中,对应的解决方式是使用 with as 语句操作上下文管理器(context manager),它能够帮助我们自动分配并且释放资源。
with open("example.txt", "r", encoding="utf-8") as file:
content = file.read()
# 在这里进行文件操作,文件会在代码块结束后自动关闭Python 的
with ... as和 Java 的try-with-resources都是自动管理资源的语法,它们在功能上非常相似,旨在确保资源(如文件、数据库连接等)在使用后被自动释放,无论是否发生异常。
此外,还有其他文件操作函数和方法可供使用,例如重命名文件、删除文件等。
【4】文件操作案例
拷贝图片
# 版本1:
# with open("卡通.png", "rb") as f_read:
# data = f_read.read()
# with open("卡通2.jpg", "wb") as f_write:
# f_write.write(data)
# 版本2:
with open("卡通3.png", "wb") as f_write:
with open("卡通.png", "rb") as f_read:
f_write.write(f_read.read())3. 下载图片和视频
import requests
# 案例1
# 爬虫
"""
当你在浏览器中访问某个网站时,通常浏览器会发送一些额外的请求头(如 User-Agent、Accept 等),以模仿正常的用户行为。但是,当你通过代码(比如 requests)访问时,它不会自动发送这些头信息,因此一些网站可能会拒绝非浏览器请求,返回 403 Forbidden 错误。
403 错误 表示服务器理解了请求,但拒绝执行该请求。常见的原因之一是服务器通过检查请求的 User-Agent(即浏览器的标识)来判断请求是否来自正常的浏览器。如果没有 User-Agent 或者它看起来像是来自爬虫工具,服务器可能会拒绝这个请求。
"""
url = "https://pic.netbian.com/uploads/allimg/240112/001654-17049898140369.jpg"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
res = requests.get(url, headers=headers)
# print(res)
# 写文件
with open("美女.jpg","wb") as f:
f.write(res.content)
# 案例2
res = requests.get("https://cdn2.zzzmh.cn/wallpaper/origin/96eaf850880911ebb6edd017c2d2eca2.jpg?response-content-disposition=attachment&auth_key=1709222400-05fa38359aefbdb5af319a5eaa8502dafc0c22eb-0-c606b2d504258a39b9c119184555c780")
with open("美女2.jpg","wb") as f:
f.write(res.content)4. openpyxl模块
openpyxl是一个功能强大的库,用于读取和写入Excel文件(.xlsx格式)。它支持创建、修改和操作Excel工作簿、工作表、单元格等。可以使用openpyxl来读取Excel文件中的数据,并进行相应的处理和分析。
下载模块
# 下载依赖
# pip install openpyxl基本使用
打开工作簿:
import openpyxl
# 读取Excel文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook['Sheet1']
# 获取单元格数据
value = sheet['A1'].value
print(value)
value = sheet['B2'].value
print(value)
sheet['A7'].value = "飞驰人生2"
# 保存修改后的Excel文件
workbook.save('example.xlsx')创建新的Excel工作簿:
import openpyxl
# 创建新工作簿
workbook = openpyxl.Workbook()
# 获取默认工作表
sheet = workbook.active
# (1) 写入数据到单元格
sheet['A1'] = 'Hello'
sheet['B1'] = 'World'
# (2) 写入一行内容
sheet.append([1, 2, 3, 4, 5])
for i in range(100):
sheet.append([i, i ** 2, i ** 3, i ** 4])
# 保存工作簿
workbook.save('new_example.xlsx')
案例应用
将爬虫到的数据存储到excel中
import requests
from openpyxl import Workbook
cookies = {
'll': '"108288"',
'bid': 'n1IbnM-UzkI',
'Hm_lvt_6d4a8cfea88fa457c3127e14fb5fabc2': '1698153214',
'_ga': 'GA1.2.1489184474.1698153214',
'_ga_Y4GN1R87RG': 'GS1.1.1698153214.1.0.1698153217.0.0.0',
'douban-fav-remind': '1',
'ap_v': '0,6.0',
'__utma': '30149280.947861648.1695648345.1708952551.1711004385.23',
'__utmb': '30149280.0.10.1711004385',
'__utmc': '30149280',
'__utmz': '30149280.1711004385.23.4.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/',
}
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'll="108288"; bid=n1IbnM-UzkI; Hm_lvt_6d4a8cfea88fa457c3127e14fb5fabc2=1698153214; _ga=GA1.2.1489184474.1698153214; _ga_Y4GN1R87RG=GS1.1.1698153214.1.0.1698153217.0.0.0; douban-fav-remind=1; ap_v=0,6.0; __utma=30149280.947861648.1695648345.1708952551.1711004385.23; __utmb=30149280.0.10.1711004385; __utmc=30149280; __utmz=30149280.1711004385.23.4.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/',
'Origin': 'https://movie.douban.com',
'Pragma': 'no-cache',
'Referer': 'https://movie.douban.com/explore',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
}
params = {
'refresh': '0',
'start': '0',
'count': '120',
'tags': '喜剧',
}
response = requests.get('https://m.douban.com/rexxar/api/v2/movie/recommend', params=params, cookies=cookies,
headers=headers)
data = response.json().get("items")
data_list = []
for i in data:
if i.get("type") == "movie":
title = i.get("title")
card_subtitle = i.get("card_subtitle")
count = i.get("rating").get("count")
value = i.get("rating").get("value")
large_pic = i.get("pic").get("large")
data_list.append([title, card_subtitle, value, count, large_pic])
wb = Workbook()
ws = wb.active
title = ['名字', '副标题', '豆瓣评分', '评分人数', "海报"]
ws.append(title)
# 将电影信息写入excel
for item in data_list:
ws.append(item)
wb.save('example.xlsx')5. 今日作业
1、将你的中文名字分别进行utf8编码再解码,GBK编码再解码
def encode(your_name, charset):
return your_name.encode(charset)
def decode(your_name, charset):
return your_name.decode(charset)
my_name = "王大锤"
print(decode(encode(my_name, "utf-8"), "utf-8"))
print(decode(encode(my_name, "gbk"), "gbk"))
2、按行读取和处理大型日志文件:对于大型日志文件,你可以按行读取文件内容,并对每行进行处理或筛选。
# 这里我以jmap导出的文件分析
with open("log.txt", "r", encoding="utf-8") as file_read:
print(file_read.readline())
print(file_read.readline())
print(file_read.readline())
3、将一个文本文件的几个计算表达式的值计算出来分别存到写到一个新的文件中
Source.txt
# 2*9-1
apple
banana
# 3-(2+5)*7-2**3
peach
# 6+8*2-(3-14)*7Target.txt
2*9-1:17
3-(2+5)*7-2**3:-54
6+8*2-(3-14)*7:99with open("Source.txt", "r") as file_reader:
lines = file_reader.readlines()
target_lines = filter(lambda l:l.startswith("#"), lines)
with open("Target.txt", "w") as file_writer:
file_writer.write("".join(list(target_lines)))4、合并多个文本文件:你可以将多个文本文件的内容合并到一个新文件中。
5、统计文件中特定单词出现的次数:你可以读取文本文件,并统计特定单词在文件中出现的次数。
def static_count(word, file):
pass