经过前两篇文章的学习,我们已经具备了阅读源码的基础。接下来,我们将正式进入 Spring Bean 生命周期 的学习。
建议的学习路径是:先理解 Bean 的生命周期,再分析容器的启动过程。原因在于:
1. Bean 的扫描与注册是生命周期的起点
容器启动时所做的核心工作之一,就是扫描并解析 BeanDefinition。这可以看作是 Bean 生命周期的 前置阶段,为后续实例化、初始化等过程做准备。
2. 先掌握“目的”,再理解“过程”
Bean 生命周期是 Spring 的核心目标,而容器启动是为实现该目标所做的准备工作。先弄清 Bean 如何创建、装配、销毁,再回头看容器如何一步步搭建这个舞台,理解起来会更加自然。
因此,我们将从 BeanDefinition 的扫描过程入手,逐步展开 Bean 生命周期的完整流程,之后再回溯到容器的启动机制。这样由核心向外围、由结果向过程的学习顺序,应该会更符合认知逻辑。
主要内容:
BeanDefinition扫描过程底层原理源码解析
MetadataReader的作用和底层原理解析
ClassMetadata的作用和底层原理解析
AnnotationMetadata的作用和底层原理解析
ExcludeFilter的作用和底层原理解析
IncludeFilter的作用和底层原理解析
@ComponentScan注解解析过程底层源码解析
@Component注解解析过程底层源码解析
@Conditional注解解析过程底层源码解析
静态内部类和内部类扫描过程底层源码解析
@Lookup注解的使用场景分析和底层原理解析
@Scope注解解析过程底层源码解析
扫描过程中beanName重复处理过程底层源码解析
一个类被重复扫描Spring处理流程底层源码解析
BeanDefinition扫描大致的入口
大致的调用链路:
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(MyConfig.class);
--->
org.springframework.context.support.AbstractApplicationContext#refresh
--->
// 默认提供了ConfigurationClassPostProcessor,所以会触发配置类的解析,从而触发扫描
invokeBeanFactoryPostProcessors(beanFactory);
// ... 这里先不看具体调用链路,而是先入为主告诉你具体是在哪个位置处理的
具体的类是:org.springframework.context.annotation.ConfigurationClassPostProcessor
具体的方法是:org.springframework.context.annotation.ConfigurationClassPostProcessor#processConfigBeanDefinitions
这个地方看代码可能会有疑问,明明还没有扫描怎么会registry.getBeanDefinitionNames();获取到值呢?
这个就要看AnnotationConfigApplicationContext类的构造方法了,或者打个断点看看大致调用链路就能明白。
注意:所谓的"解析配置类"并不仅仅是处理@Configuration注解本身,更重要的是解析配置类上的其他注解,比如@ComponentScan、@Import、@Bean等。========================================细节补充===============================
这里我们看下org.springframework.context.annotation.ConfigurationClassUtils#checkConfigurationClassCandidate方法(此方法判断一个类是否应该被当作配置类处理。如果返回true,Spring就会把它标记为配置类并走配置类解析流程,但解析后可能发现它并没有实际的配置内容。),通过这里可以理解配置类的两种模式(这里与配置类加不加@Configuration有关,让你彻底明白有什么区别),关键代码:
Map<String, Object> config = metadata.getAnnotationAttributes(Configuration.class.getName());
if (config != null && !Boolean.FALSE.equals(config.get("proxyBeanMethods"))) {
// 情况1:有@Configuration且proxyBeanMethods不为false → FULL模式
beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_FULL);
}
// Spring6引入这个地方myConfig的beanDef.getAttribute(CANDIDATE_ATTRIBUTE)会是True,肯定是之前容器启动过程中打标了的
// @Component、@ComponentScan、@Import、@ImportResource 含有这四个注解的类就是配置类候选者(注意:只是候选者)
else if (config != null || Boolean.TRUE.equals(beanDef.getAttribute(CANDIDATE_ATTRIBUTE)) ||
isConfigurationCandidate(metadata)) {
// 情况2:有@Configuration但proxyBeanMethods为false → LITE模式
// 情况3:有CANDIDATE_ATTRIBUTE标记 → LITE模式
// 情况4:通过isConfigurationCandidate检查 → LITE模式
beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_LITE);
}
else {
return false;
}参考文章:《Spring配置类深度解析:从@Configuration到代理模式的完整指南》
这篇文章我们只分析扫描的逻辑,扫描是解析配置类中的一个步骤,这里的主要目的只是先理解何谓配置类。
=============================================================================
下面回归正题:
具体的解析配置类代码:
// 配置类解析器
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
然后会调用:
// 解析所有配置类
parser.parse(candidates);
然后继续调用:
configClass = parse(annotatedBeanDef, holder.getBeanName());
然后继续调用:
org.springframework.context.annotation.ConfigurationClassParser#processConfigurationClass
此方法就是一个核心的方法,再往下走:
org.springframework.context.annotation.ConfigurationClassParser#doProcessConfigurationClass
就到了一个更核心的解析配置类的方法,而我们今天要分析的主要是扫描,所以只关注ComponentScan注解的处理。下面是核心代码,也就是扫描处理的入口代码,方法名如下org.springframework.context.annotation.ConfigurationClassParser#doProcessConfigurationClass
// Search for locally declared @ComponentScan annotations first.
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScan.class, ComponentScans.class,
MergedAnnotation::isDirectlyPresent);
// Fall back to searching for @ComponentScan meta-annotations (which indirectly
// includes locally declared composed annotations).
if (componentScans.isEmpty()) {
componentScans = AnnotationConfigUtils.attributesForRepeatable(sourceClass.getMetadata(),
ComponentScan.class, ComponentScans.class, MergedAnnotation::isMetaPresent);
}
if (!componentScans.isEmpty()) {
List<Condition> registerBeanConditions = collectRegisterBeanConditions(configClass);
if (!registerBeanConditions.isEmpty()) {
throw new ApplicationContextException(
"Component scan for configuration class [%s] could not be used with conditions in REGISTER_BEAN phase: %s"
.formatted(configClass.getMetadata().getClassName(), registerBeanConditions));
}
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
// 解析@ComponentScan注解,也就是进行扫描
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
// 遍历扫描结果,看是否扫描出了新的配置类,然后进行解析
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}从源码可以看出,@ComponentScan使用了@Repeatable(ComponentScans.class)注解,这是Java 8引入的可重复注解特性。这意味着在Java 8+中,可以在同一个类上直接标注多个@ComponentScan注解,编译器会将其处理为@ComponentScans容器注解的形式。
@ComponentScans是Java 8之前(以及向后兼容)的唯一方式,即使在Java 8中,如果需要在运行时获取所有@ComponentScan注解,Spring框架会通过getAnnotationsByType()方法来处理可重复注解。
可重复注解不仅仅是语法糖,它涉及编译器、反射API和注解处理器的协同工作。
具体解析某一个@ComponentScan注解的方法应该是:org.springframework.context.annotation.ComponentScanAnnotationParser#parses
@ComponentScan注解使用
具体见另外一篇幅文章《ComponentScan注解属性详解》。
ExcludeFilter和IncludeFilter
这里再详细介绍下@ComponentScan注解的过滤器机制。
这两个Filter是Spring扫描过程中用来过滤的。ExcludeFilter表示排除过滤器(相当于黑名单),IncludeFilter表示包含过滤器(相当于白名单)。
比如以下配置,表示扫描com.tuling这个包下面的所有类,但是排除UserService类,也就是就算它上面有@Component注解也不会成为Bean。
@ComponentScan(value = "com.tuling",
excludeFilters = {@ComponentScan.Filter(
type = FilterType.ASSIGNABLE_TYPE,
classes = UserService.class)})
public class MyConfig {
}再比如以下配置,就算UserService类上没有@Component注解,它也会被扫描成为一个Bean。
@ComponentScan(value = "com.tuling",
includeFilters = {@ComponentScan.Filter(
type = FilterType.ASSIGNABLE_TYPE,
classes = UserService.class)})
public class MyConfig {
}FilterType 包括以下几种类型:
ANNOTATION:检查是否包含特定注解。
ASSIGNABLE_TYPE:检查是否为特定类。
ASPECTJ:检查是否符合特定 AspectJ 表达式。
REGEX:检查是否匹配特定正则表达式。
CUSTOM:自定义过滤条件。
在Spring的扫描逻辑中,默认会添加一个AnnotationTypeFilter给includeFilters,表示默认情况下Spring扫描过程中会认为类上有@Component注解的就是Bean。
源码:org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#registerDefaultFilters
还有一些JakartaEE的注解判断有的话也会增加includeFilters,比如@ManagedBean、@Named。
Spring启动的时候会进行扫描,会先调用org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#scanCandidateComponents(String basePackage)
扫描某个包路径,并得到BeanDefinition的Set集合。
这里注意两个点:
先要看清楚扫描的包路径,如果没有指定则是@ComponentScan注解所有在的包及其子包,只有在扫描的包路径下的过滤器才生效
includeFilters可以有多个,只要匹配上一个就可以,Spring默认会有includeFilters,可以通过useDefaultFilters属性关闭
组件需要同时满足:匹配includeFilters AND 不匹配excludeFilters,不是简单的优先级问题,而是一个逻辑与(AND) 的关系
parse方法源码走读
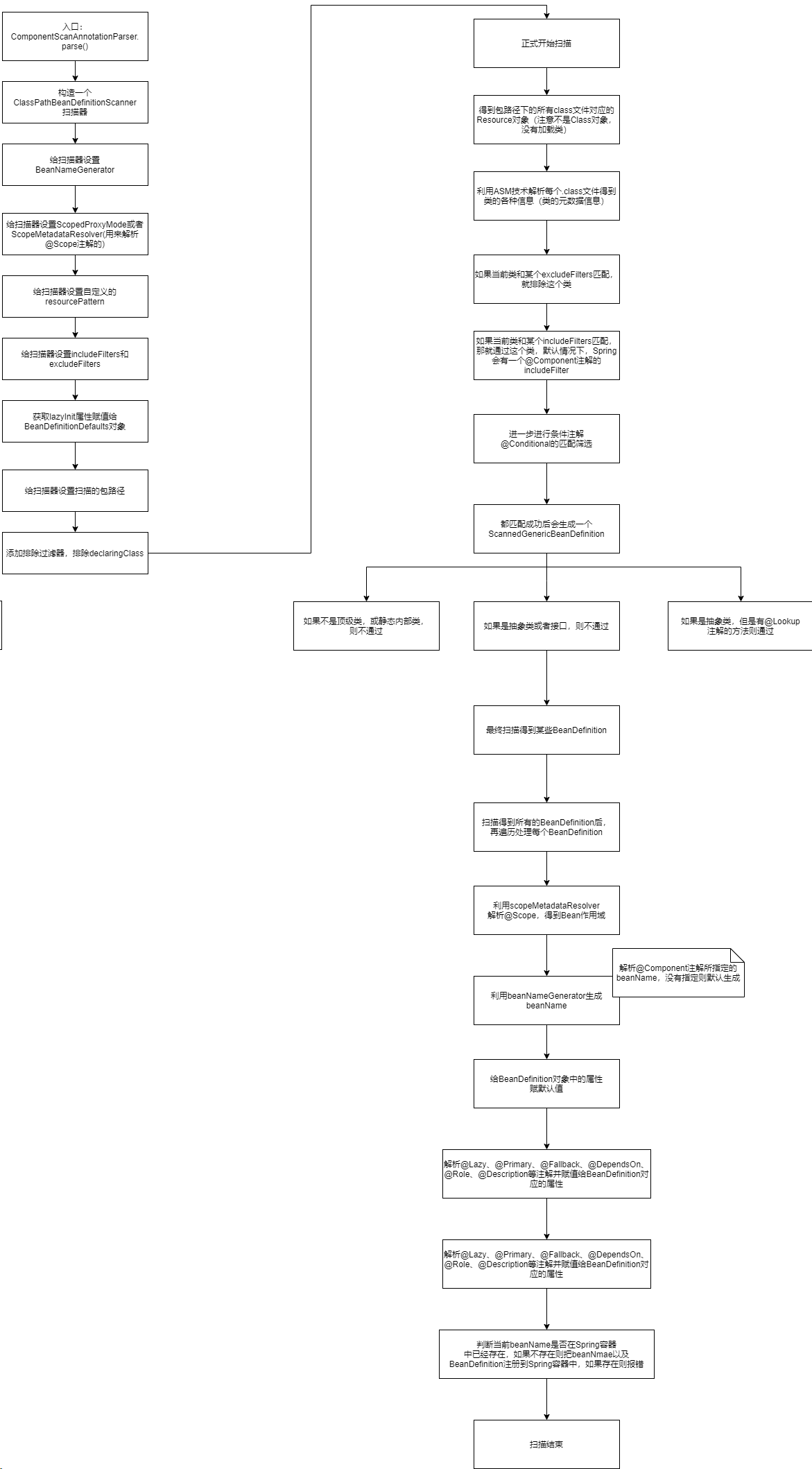
org.springframework.context.annotation.ComponentScanAnnotationParser#parses方法是具体解析@ComponentScan的方法,我们可以进行一个大致的走读:
// 解析某一个@ComponentScan
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, String declaringClass) {
// 构造一个扫描器
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
// 获取自定义的BeanNameGenerator
Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
BeanUtils.instantiateClass(generatorClass));
// 获取自定义的ScopedProxyMode
ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
}
else {
Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
}
// 获取自定义的resourcePattern
scanner.setResourcePattern(componentScan.getString("resourcePattern"));
for (AnnotationAttributes includeFilterAttributes : componentScan.getAnnotationArray("includeFilters")) {
List<TypeFilter> typeFilters = TypeFilterUtils.createTypeFiltersFor(includeFilterAttributes, this.environment,this.resourceLoader, this.registry);
for (TypeFilter typeFilter : typeFilters) {
scanner.addIncludeFilter(typeFilter);
}
}
for (AnnotationAttributes excludeFilterAttributes : componentScan.getAnnotationArray("excludeFilters")) {
List<TypeFilter> typeFilters = TypeFilterUtils.createTypeFiltersFor(excludeFilterAttributes, this.environment,
this.resourceLoader, this.registry);
for (TypeFilter typeFilter : typeFilters) {
scanner.addExcludeFilter(typeFilter);
}
}
// 获取自定义的lazyInit
boolean lazyInit = componentScan.getBoolean("lazyInit");
if (lazyInit) {
scanner.getBeanDefinitionDefaults().setLazyInit(true);
}
// 获取自定义的basePackages
Set<String> basePackages = new LinkedHashSet<>();
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
Collections.addAll(basePackages, tokenized);
}
// 获取配置的类所在的包路径作为扫描路径
for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
// 如果basePackages为空,则将declaringClass的包路径作为扫描路径
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
// 添加排除过滤器,排除declaringClass
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
@Override
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
// 扫描basePackages中的所有类,并注册到BeanDefinitionRegistry中
return scanner.doScan(StringUtils.toStringArray(basePackages));
}这个方法更多的是在解析@ComponentScan中定义的属性赋值给扫描器,目前大致也了解即可,更核心的方法是:org.springframework.context.annotation.ClassPathBeanDefinitionScanner#doScan
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
// 扫描basePackages中的所有类,并注册到BeanDefinitionRegistry中
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
// 获取bean的scope
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 生成beanName
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 给BeanDefinition对象中的属性赋默认值
if (candidate instanceof AbstractBeanDefinition abstractBeanDefinition) {
postProcessBeanDefinition(abstractBeanDefinition, beanName);
}
// 解析@Lazy、@Primary、@Fallback、@DependsOn、@Role、@Description等注解并赋值给BeanDefinition对应的属性
if (candidate instanceof AnnotatedBeanDefinition annotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations(annotatedBeanDefinition);
}
// 检查beanName是否已存在
if (checkCandidate(beanName, candidate)) {
// BeanDefinitionHolder的作用是在BeanDefinition的基础上添加了beanName
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
// 如果设置了ScopedProxyMode,则会生成一个新的BeanDefinition,类型为ScopedProxyFactoryBean
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 注册beanDefinition
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}下面我们看findCandidateComponents方法,这个方法名要注意,返回的只是候选BeanDefinition,意思是说最终不一定这个集合里面所有的BeanDefinition都需要注册。org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#findCandidateComponents源码:
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
// 大部分情况会走到这个地方
return scanCandidateComponents(basePackage);
}
}componentsIndex是一个优化机制,后面有文章单独学习
在阅读org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#scanCandidateComponents方法之前,我们先了解一下Spring中ASM技术相关的API、@Conditional注解、@Lookup注解。
MetadataReader、ClassMetadata、AnnotationMetadata
在Spring中需要去解析类的信息,比如类名、类中的方法、类上的注解,这些都可以称之为类的元数据,所以Spring中对类的元数据做了抽象,并提供了一些工具类。
MetadataReader表示类的元数据读取器,默认实现类为SimpleMetadataReader。比如:
public class Main {
public static void main(String[] args) throws IOException {
SimpleMetadataReaderFactory simpleMetadataReaderFactory = new SimpleMetadataReaderFactory();
// 构造一个MetadataReader
MetadataReader metadataReader = simpleMetadataReaderFactory.getMetadataReader("com.hexon.service.UserService");
// 得到一个ClassMetadata,并获取了类名
ClassMetadata classMetadata = metadataReader.getClassMetadata();
System.out.println(classMetadata.getClassName());
System.out.println(classMetadata.getSuperClassName());
System.out.println(classMetadata.getMemberClassNames());
// 获取一个AnnotationMetadata,并获取类上的注解信息
AnnotationMetadata annotationMetadata = metadataReader.getAnnotationMetadata();
for (String annotationType : annotationMetadata.getAnnotationTypes()) {
System.out.println(annotationType);
}
// 假如类上使用的是@Component注解
System.out.println(annotationMetadata.hasAnnotation(Component.class.getName())); // true
System.out.println(annotationMetadata.hasMetaAnnotation(Component.class.getName())); // false 判断类上的注解是否是“被 @Component 标注的注解”。
System.out.println(annotationMetadata.hasAnnotatedMethods(Bean.class.getName()));
}
}需要注意的是,SimpleMetadataReader去解析类时,底层使用的是ASM技术。
为什么要使用ASM技术,Spring启动的时候需要去扫描,如果指定的包路径比较宽泛,那么扫描的类是非常多的,那如果在Spring启动时就把这些类全部加载进JVM了,这样不太好,所以使用了ASM技术。
另外这里温习一个JVM知识点:
A.class(只访问类字面量)只会加载类,不初始化(静态代码块不执行)
@Conditional注解的使用
@Component
@Conditional(MyCondition.class)
public class UserService {
public void test() {
System.out.println(user.getName());
}
}public class MyCondition implements Condition {
@Override
public boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) {
try {
context.getClassLoader().loadClass("com.hexon.UserDao");
return true;
} catch (ClassNotFoundException e) {
return false;
}
}
}public class UserDao {
}SpringBoot中就有很多地方会用到类似这种条件判断的逻辑
@Lookup注解
在后面看源码的过程中,会有一个判断是抽象类,并且此类有@Lookup标注的方法,所以这里我们先来看看@Lookup的作用。
我们把UserService改成抽象类:
@Component
public abstract class UserService {
public void test() {
System.out.println("hello danny");
}
}此时,直接getBean("userService")会报错,但是如果我们在UserService类中定义一个标注的@Lookup的方法:
@Component
public abstract class UserService {
@Lookup
public abstract void a();
public void test() {
System.out.println("hello danny");
}
}这里并不关心声明与方法体
测试:
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(MyConfig.class);
UserService userService = applicationContext.getBean(UserService.class);
System.out.println(userService); // 代理类:com.hexon.service.UserService$$SpringCGLIB$$0@1356d4d4
// userService.a(); // 调用a方法会报错:No qualifying bean of type 'void' availables
}
}放进容器里的 Bean 根本不是你的抽象类本身,而是 Spring 生成的 CGLIB 代理子类实例。
这个代理类会重写标注@Lookup的方法,内部会根据方法返回类型去getBean(lookupReturnType),上面a方法没有返回值,所以当调用a方法的时候会报错,但是你如果只是获取UserService类型的Bean是没有问题的,因为代理对象已经放入了容器。
下面来看看@Lookup的一个具体的用法。
@Component
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public class OrderService {
}@Component
public class UserService {
@Autowired
OrderService orderService;
public void test() {
System.out.println(orderService);
}
}public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(MyConfig.class);
UserService userService = applicationContext.getBean(UserService.class);
userService.test();
userService.test();
userService.test();
}
}
输出结果:
com.hexon.service.OrderService@55b699ef
com.hexon.service.OrderService@55b699ef
com.hexon.service.OrderService@55b699ef默认情况下,单例 Bean(UserService)只会在创建时注入一次依赖(OrderService)。
即使被注入的 Bean 是 prototype,也只会创建一次,后续使用的都是同一个实例。
如果业务上要求每次调用都得到一个新的 prototype 实例,就必须使用
@Lookup(或ObjectFactory,Provider等)。@Lookup的本质是:Spring 会为该方法生成代理,每次调用时动态执行getBean(),从而返回新的 prototype Bean。
改造UserService方法:
@Component
public class UserService {
@Autowired
OrderService orderService;
public void test() {
System.out.println(getOrderService());
}
@Lookup // 还可以指定名字,如果指定名字会先根据名字,我这里没有指定就是直接根据getOrderService方法的返回值类型获取Bean
public OrderService getOrderService() { // 但方法名是任意定义的,Spring 完全不关心这个方法名和方法体的内容
return null;
}
}此时再运行上面的测试类Main,输出结果如下:
com.hexon.service.OrderService@2abf4075
com.hexon.service.OrderService@770d3326
com.hexon.service.OrderService@4cc8eb05s原理解释:
这个实际是走的代理对象的getOrderService()逻辑,相当于是多次调用context.getBean(OrderService.class),所以每次获取的实例不一样。
顶级类
在后面的源码判断中有一个metadata.isIndependent()的方法,这里也可以演示下内部类的情况。
@Component // 外部类必须加@Component
public class UserService {
@Component("member")
public class Member { }
public void test() {
System.out.println("UserService#test....");
}
}这里Member它就不是独立类,但是它依然可以注册BeanDefinition,具体来说是ConfigurationClassBeanDefinitionReader#doProcessConfigurationClass方法里有一个递归和处理过程,它调用了org.springframework.context.annotation.ConfigurationClassParser#processMemberClasses方法
或者
public class UserService {
@Component("member")
public static class Member { }
public void test() {
System.out.println("UserService#test....");
}
}静态类部类可以脱离外部类独立,这都是java内部类基础语法的问题
测试:
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(MyConfig.class);
System.out.println(applicationContext.getBean("member"));
}
}scanCandidateComponents方法源码分析
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// .class文件对应的Resource对象
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
String filename = resource.getFilename();
if (filename != null && filename.contains(ClassUtils.CGLIB_CLASS_SEPARATOR)) {
// Ignore CGLIB-generated classes in the classpath
continue;
}
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
try {
// 利用ASM技术解析每个.class文件得到类的各种信息(类的元数据信息)
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// 利用excludeFilters和includeFilers来判断当前class是否为bean,条件注解
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
// 不是接口或者抽象类,如果是抽象类,但是有@Lookup注解的方法则通过
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (FileNotFoundException ex) {
if (traceEnabled) {
logger.trace("Ignored non-readable " + resource + ": " + ex.getMessage());
}
}
catch (ClassFormatException ex) {
if (shouldIgnoreClassFormatException) {
if (debugEnabled) {
logger.debug("Ignored incompatible class format in " + resource + ": " + ex.getMessage());
}
}
else {
throw new BeanDefinitionStoreException("Incompatible class format in " + resource +
": set system property 'spring.classformat.ignore' to 'true' " +
"if you mean to ignore such files during classpath scanning", ex);
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException("Failed to read candidate component class: " + resource, ex);
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}两个isCandidateComponent方法内部的逻辑,都在前面介绍过了,自己点进去看看就清楚了。
看完此方法后,就回到了org.springframework.context.annotation.ClassPathBeanDefinitionScanner#doScan方法中的:
// 扫描basePackages中的所有类,并注册到BeanDefinitionRegistry中
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);这行代码是真正的完成了扫描,扫描某个包下的class文件,得到符合条件的BeanDefinition。
doScan方法阅读
源码位置:org.springframework.context.annotation.ClassPathBeanDefinitionScanner#doScan
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
// 扫描basePackages中的所有类,并注册到BeanDefinitionRegistry中
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
// 获取bean的scope
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 生成beanName,会读取@Component的值
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 给BeanDefinition对象中的属性赋默认值
if (candidate instanceof AbstractBeanDefinition abstractBeanDefinition) { // JDK新语法
postProcessBeanDefinition(abstractBeanDefinition, beanName);
}
// 解析@Lazy、@Primary、@Fallback、@DependsOn、@Role、@Description等注解并赋值给BeanDefinition对应的属性
if (candidate instanceof AnnotatedBeanDefinition annotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations(annotatedBeanDefinition);
}
// 检查beanName是否已存在
if (checkCandidate(beanName, candidate)) {
// BeanDefinitionHolder的作用是在BeanDefinition的基础上添加了beanName
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
// 如果设置了ScopedProxyMode,则会生成一个新的BeanDefinition,类型为ScopedProxyFactoryBean
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 注册beanDefinition
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}基本就是获取到所有候选的BeanDefinition后,再设置一些属性的值,最后注册beanDefinition。这里我们先跳过checkCandidate,看看registerBeanDefinition的具体逻辑,通过断点的方式我们定位到:
org.springframework.beans.factory.support.DefaultListableBeanFactory#registerBeanDefinition方法中。此方法里面有个允许覆盖的检查操作。但此方法我们先不会细看,后面分析@Bean的时候会细看,本文只是讨论扫描。
再就来看下org.springframework.context.annotation.ClassPathBeanDefinitionScanner#checkCandidate方法。
此方法中有个判断兼容的方法:org.springframework.context.annotation.ClassPathBeanDefinitionScanner#isCompatible
它内部用到了source,这个source就可以理解成文件,在前面分析org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#scanCandidateComponents方法时,有一步给ScannedGenericBeanDefinition设置了source。
在扫描的过程中,出现兼容的情况,一般可能是指定了多个包扫描路径,然后重复扫描了。兼容的就直接return false,就不会重新注册。我们这里只是分析扫描的过程中,对于@Bean和扫描时的冲突了,会在后面的学习中分析。
不兼容就是冲突的情况,这里我们可以演示一下Bean定义冲突的情况。
@Component("userService")
public class OrderService {
}@Component
public class UserService {
public void test() {
System.out.println("UserService#test....");
}
}输出:
Caused by: org.springframework.context.annotation.ConflictingBeanDefinitionException: Annotation-specified bean name 'userService' for bean class [com.hexon.service.UserService] conflicts with existing, non-compatible bean definition of same name and class [com.hexon.service.OrderService]最后我们回到org.springframework.context.annotation.ConfigurationClassParser#doProcessConfigurationClass方法
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
// 解析@ComponentScan注解,也就是进行扫描
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
// 遍历扫描结果,看是否扫描出了新的配置类,然后进行解析
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
// 继续解析
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}这个代码是我们最开始说的入口,当扫描出BeanDefinition后还有一个处理,那就是可能这些Bean也可能是配置类,所以会去继续解析。具体我们后面细讲。
总结
本文我们把BeanDefinition扫描的核心源码分析了一遍,当然注册BeanDefinition的方式不止有扫描,其他方式后面我们会单独分析。