课程内容:
索引数据结构红黑树,Hash,B+树详解
千万级数据表如何用B+树索引快速查找
聚集索引&聚簇索引&稀疏索引到底是什么
为什么DBA总推荐使用自增主键做索引
联合索引底层数据结构又是怎么样的
Mysql最左前缀优化原则是怎么回事
Mysql8中最左前缀的变化
1、索引数据结构的选择
索引是帮助MySQL高效获取数据的排好序的数据结构。
常见的索引数据结构:
二叉树
红黑树
Hash表
B-Tree
为什么索引能帮助MySQL高效获取数据呢?
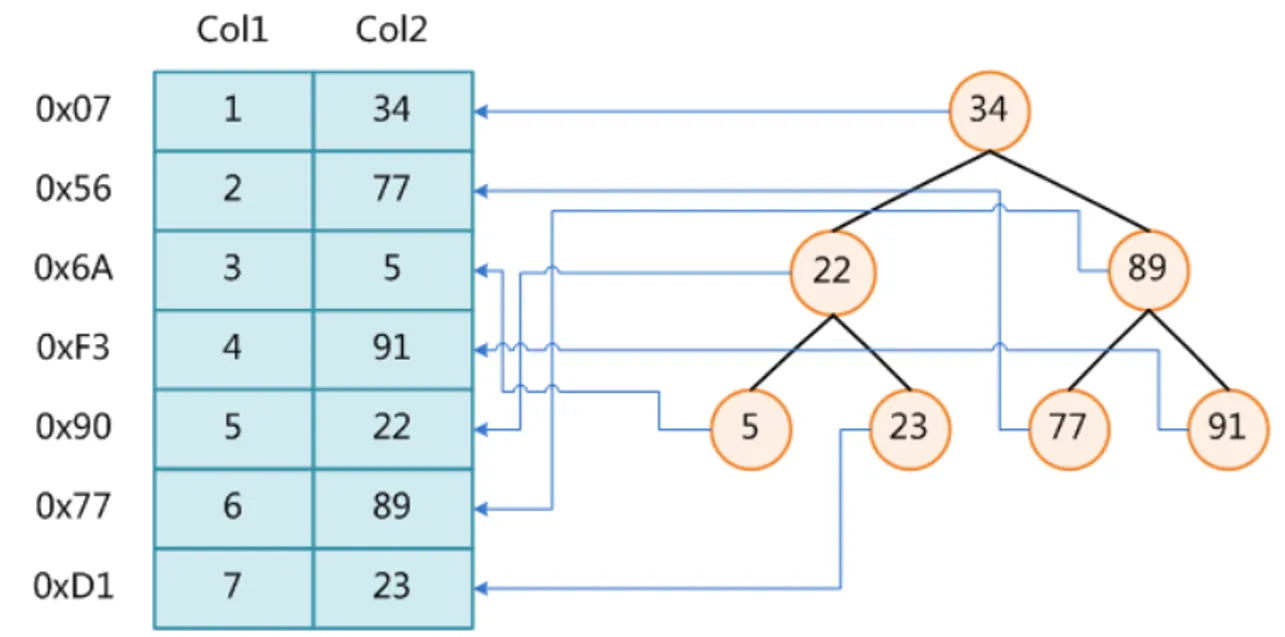
select * from t where t.col2 = 89;如上的SQL语句,如果没有索引我们查找时会一行一行的比对查找。而我们的数据存储在磁盘上,一张表的数据在磁盘上是随机分布的,不一定是挨着的。查询时需要从磁盘进行I/O操作拿到数据再在内存中比对,如果一个表的数据很多,I/O次数就会很多,所以我们可以减少拿到我们这行数据的查找次数,将查询次数控制在一定范围内效率就会比较高。有索引的话那么MySQL就不需要把所有的数据页加载到内存中,或者说只需要加载更少的数据页,减少了I/O操作,因此会提高效率。
下面补充一些常识知识:
补充:
一次I/O大概需要多长时间?
一般情况下,磁盘的一次I/O操作的时间取决于多个因素,包括磁盘类型(机械硬盘或固态硬盘)、磁盘转速、数据传输速率、磁盘负载、操作系统的优化等。以下是一些估计值:
1. 机械硬盘(HDD):一般情况下,机械硬盘的寻道时间大约在3-9毫秒,旋转延迟时间(等待数据扇区旋转到磁头位置)取决于磁盘的转速(通常为5400 RPM、7200 RPM或更高),一般在2-10毫秒。因此,机械硬盘的一次I/O操作可能需要10-20毫秒左右。
2. 固态硬盘(SSD):固态硬盘没有机械部件,因此寻道时间和旋转延迟时间几乎为零。固态硬盘的读取延迟一般在0.1毫秒以下,写入延迟也在几毫秒以内。因此,固态硬盘的一次I/O操作通常在0.1-5毫秒左右。
需要注意的是,这些时间仅供参考,实际情况可能会有所不同。另外,随着技术的发展和硬件的优化,磁盘的I/O操作速度也在不断提升。在实际应用中,可以通过性能测试和基准测试来评估磁盘的I/O性能,以便更准确地了解磁盘操作的时间消耗。
什么是一次I/O?
一次IO(Input/Output)指的是一次数据传输操作,即将数据从磁盘读取到内存或者将数据从内存写入到磁盘的过程。在计算机系统中,一次IO的大小取决于多个因素,包括硬件设备、操作系统和应用程序的设置等。
在传统的机械硬盘(HDD)中,一次IO的大小通常是一个数据块(Block)的大小,数据块的大小一般为4KB或8KB。这意味着每次IO操作可以读取或写入4KB或8KB的数据。
对于固态硬盘(SSD)来说,由于其内部结构不同于机械硬盘,一次IO的大小可以更灵活地设置。固态硬盘通常能够支持更大的IO操作,可以一次性读取或写入更多的数据,提高数据传输效率。
总的来说,一次IO可以读取或写入的数据量取决于硬件设备的特性和系统设置。在进行IO操作时,合理设置IO大小可以提高数据传输效率,减少IO次数,从而提升系统性能。
基于上述原因,就出现了索引这种数据结构,下面来讨论下各种常见的数据结构。
二叉树
我们把树的节点中存放key-value键值对,比如key就是索引字段的值,value就是索引所在行的磁盘文件地址。查找时从根节点查找,二叉树的特点:右边的元素大于父元素,左边的元素小于父元素。这样上述的SQL只需要经过两次查找就可以了。但是MySQL并没有选择二叉树做为索引结构,因为对于值是单边增长的数据列,最终会变成类似链表的结构,对我们查询没有帮助。
参考:数据结构网站
红黑树
属于二叉平衡树,它主要是会对维护的节点进行自动平衡。MySQL并没有选择红黑树做为索引结构,因为数据量大的情况,树的高度不可控,如果要查询的节点的叶子节点上,那么从根节点开始查询次数会比较大。
B-Tree
现在主要的问题就是解决树的高度太高的问题,因此考虑B树,它的特点如下:
叶节点具有相同的深度,叶节点的指针为空
所有索引元素不重复
节点中的数据索引从左到右递增排列
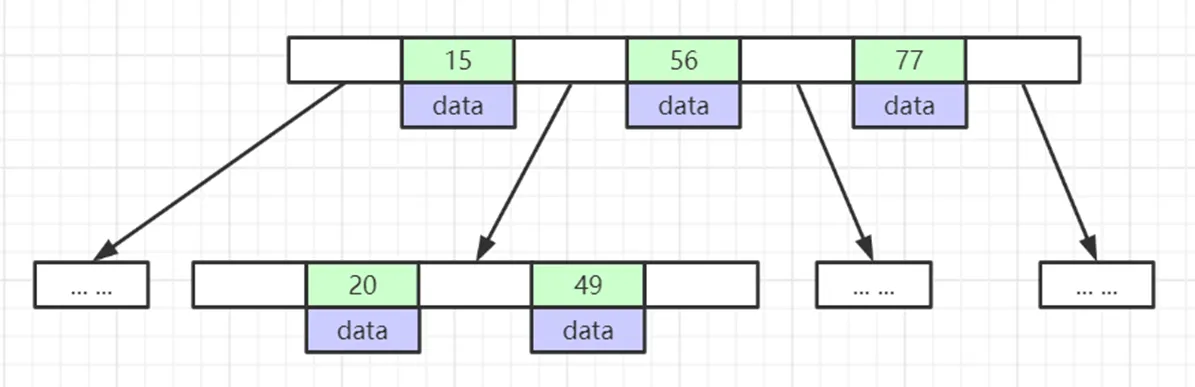
总结:B树主要就是一个大的节点里面放很多小的索引元素,但MySQL没有使用这个结构,而是用的B+树。
B+树(B-Tree变种)
非叶子节点不存储data,只存储索引(冗余,但B树不冗余),可以放更多的索引
叶子节点包含所有索引元素
叶子节点用指针连接,提高区间访问的性能
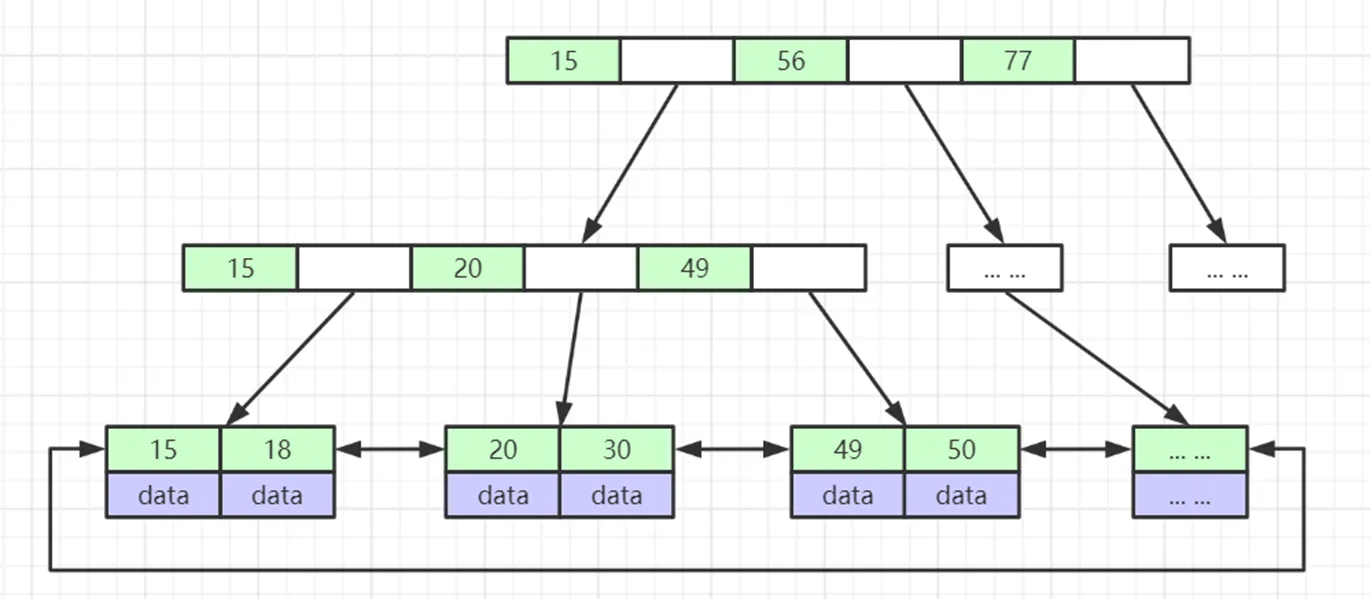
叶子节点可以看成是一页一页的数据页,非叶子节点是一种冗余索引,会取每一页的第一个元素(处于中间位置的元素);每个节点中的数据索引从左到右递增排列(B树的特征),无论是节点内还是节点之间都是排好序的。叶子节点之间有双向指针。
使用B+树查找数据的过程大致是:
如果要查找col=30,从根节点开始查找,把根节点的元素全部load到RAM中,可以使用折半查找(二分查找)等算法快速定位30位于15和56之间,通过指针就可以找到下个数据页在磁盘的地址,再把下个数据页load到RAM,继续折半查找,直到找到30,再根据磁盘地址load进内存返回。
DeepSeek
上面的回答感觉不完美,这里我要思考下,面试的时候怎么组织语言回答?
“MySQL InnoDB使用B+树,其非叶子节点存储键值和子节点指针。键值来自子节点分裂时提取的第一个键(例如叶子节点
[10,20]和[30,40]分裂后,父节点插入30)。 这种设计使非叶子节点更紧凑,能在内存缓存更多层级。叶子节点通过双向链表串联,高效支持WHERE id>100这类范围查询。 以16KB页大小为例,4层B+树可支持数十亿数据,且查询仅需3~4次磁盘I/O。”
查看mysql文件页大小(16K):
SHOW GLOBAL STATUS like 'Innodb_page_size';为什么mysql页文件默认16K?
假设我们一行数据大小为1K,那么一页就能存16条数据,也就是一个叶子节点能存16条数据;再看非叶子节点,假设主键ID为bigint类型,那么长度为8B,指针大小在Innodb源码中为6B,一共就是14B,那么一页里就可以存储16K/14=1170个(主键+指针)
那么一颗高度为2的B+树能存储的数据为:1170 * 16=18720条,一颗高度为3的B+树能存储的数据为:
1170 * 1170 * 16=21902400(千万级条)
由此可见,千万级别的表合理走索引都只需要3次磁盘I/O,所以索引能提高查询效率!
而且根节点可能是常驻内存的,因MySQL版本而异非叶子节点也可能是在内存中的,所以I/O次数可能更少!
MySQL为什么不使用B树?(B树与B+树的区别)
B+树的非叶子节点不存储data,就是让它空出来,使用每页能存储更多索引。因为B+树的高度就是由非叶子节点中能放索引元素的多少来决定的。
2、索引在磁盘上是如何存储的?
这里要针对不同存储引擎来说,注意的是存储引擎一般是针对表来说的,而不是整个数据库。
2.1 MyISAM索引文件和数据文件是分离的(非聚集)
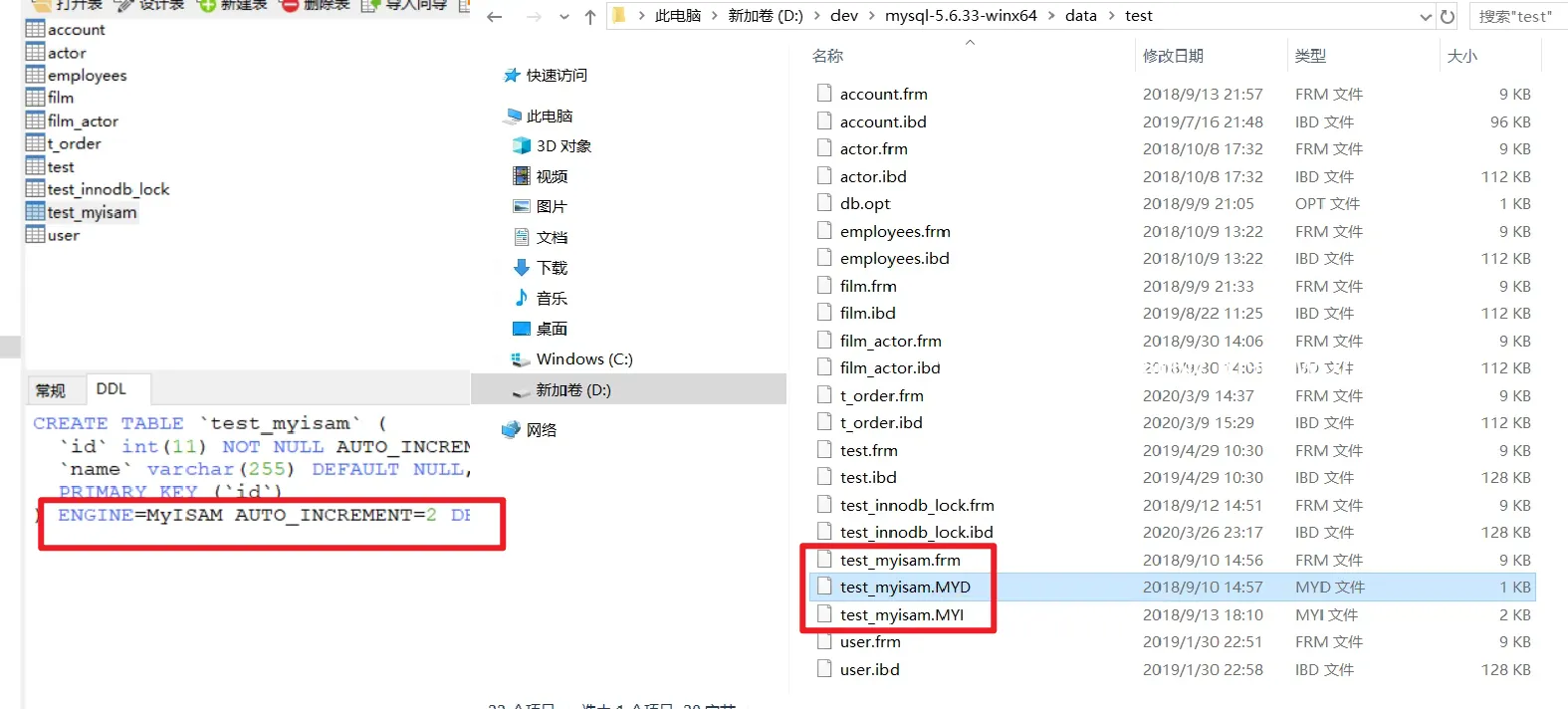
.frm文件(Fomat)是表定义文件,用于存储表的结构定义信息。每个MySQL表都对应一个.frm 文件,其中包含了表的元数据,如列名、数据类型、索引信息等。
.MYD:D,是Data的意思。
.MYI:I,是Index的意思。
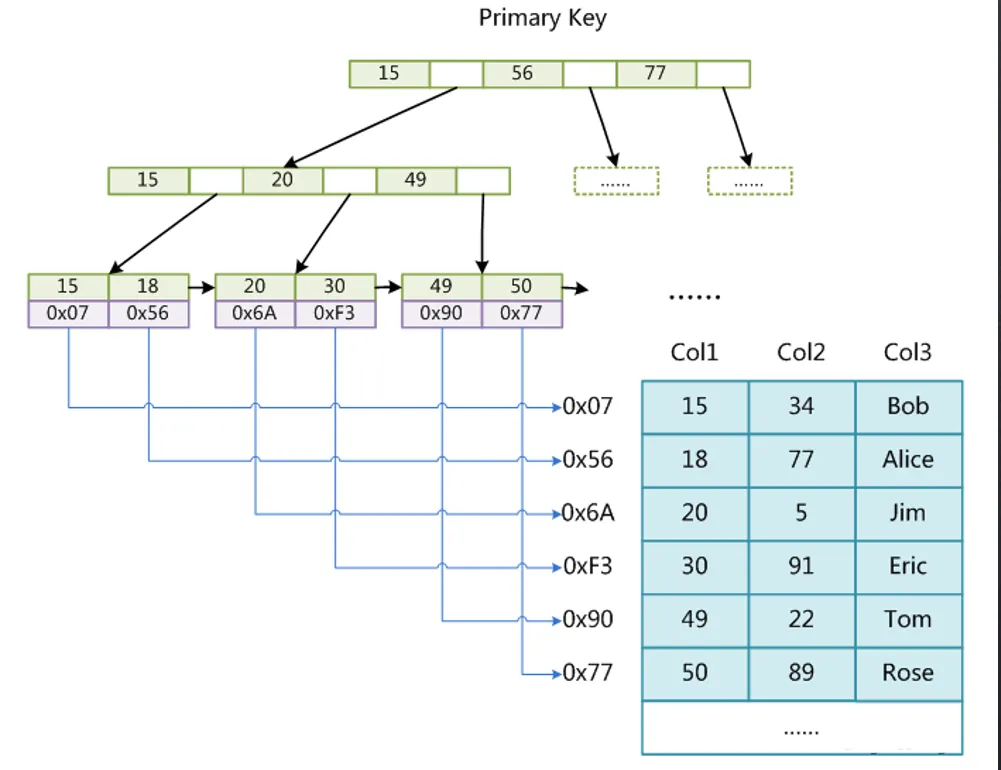
上图是索引结构,下面来说下MyISAM存储引擎查找数据的过程:
以查找col1=30为例,会先根据MYI文件中的索引结构定位到30那一行在MYD文件的地址,再去MYD文件中定位具体的数据。
2.2 InnoDB索引实现(聚集)
表数据文件本身就是按B+Tree组织的一个索引结构文件
聚集索引-叶节点包含了完整的数据记录
为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
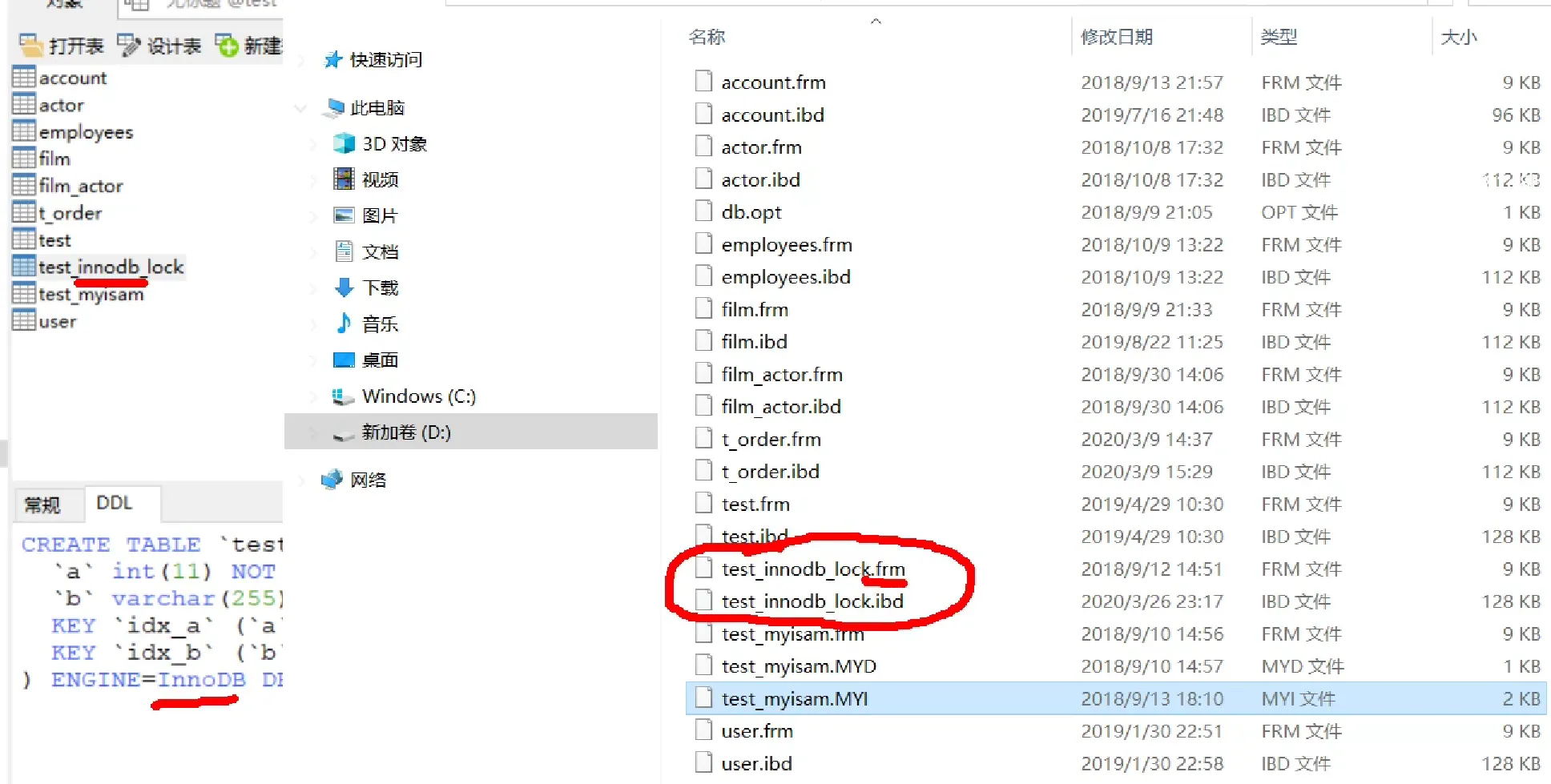
在 MySQL 中,对于 InnoDB 存储引擎,每个表都有一个单独的 .ibd 文件,该文件包含表的数据和索引。如果一张表有多个索引,这些索引通常会存储在同一个 .ibd 文件中。
InnoDB 存储引擎使用聚集索引的方式来组织数据。在 InnoDB 中,主键索引(Primary Key)实际上就是数据行的物理排序顺序,因此主键索引总是存在的。除了主键索引外,其他辅助索引(Secondary Index)也会存储在同一个 .ibd 文件中。
每个索引在 .ibd 文件中都有自己的数据结构来存储索引键和指向数据行的引用。这种设计使得 InnoDB 存储引擎能够高效地管理数据和索引,同时保持数据的一致性和可靠性。
因此,无论一张表有多少个索引,这些索引通常会存储在同一个 .ibd 文件中,与表的数据一起管理和维护。
具体的索引结构如下图所示:
InnoDB的主键索引
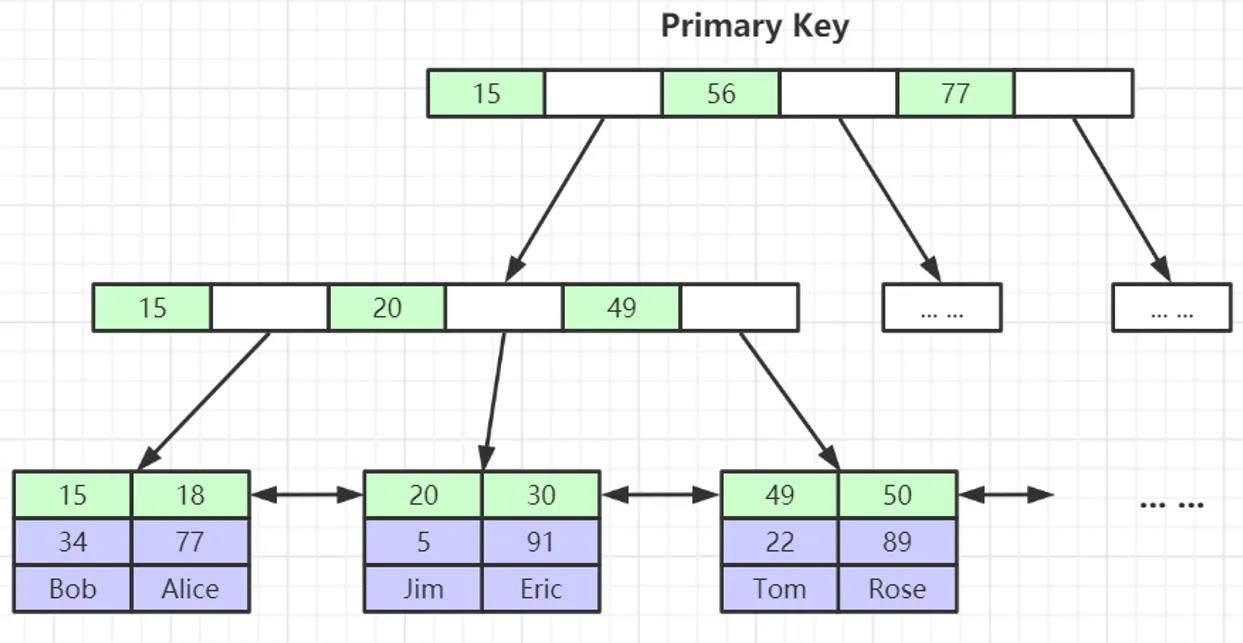
InnoDB的主键索引其实就是聚集索引,而相反的MyISAM的索引就是非聚集索引。
聚集索引 = 聚簇索引
非聚集索引 = 非聚簇索引 = 稀疏索引
为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
设置主键的原因:
因为MySQL要构建B+树的结构,如果你不指定主键,那么MySQL会自动选择所有值都不相同的列来维护B+树,如果找不到这种列就会用类似于内置生成的row_id的隐藏列。
使用整型的原因:
其一整型的比较大小速度快点,另外更加节省服务器固态硬盘的存储空间。
为什么要自增呢?
降低索引的维护成本,因为维护索引时要保证有序,防止在节点元素中间插入元素,导致树又重新平衡。
聚集索引和非聚集索引查找数据的速度哪个更快?
聚集的快点,非聚集索引要跨文件查找,类似于回表的操作。
对于 MyISAM 中的主键索引和非主键索引的存储结构没有区别,但是InnoDB的就有区别:
叶子节点存储的是组织聚集索引的那个值(注意不一定是主键)。
原因:一致性,节省存储空间。
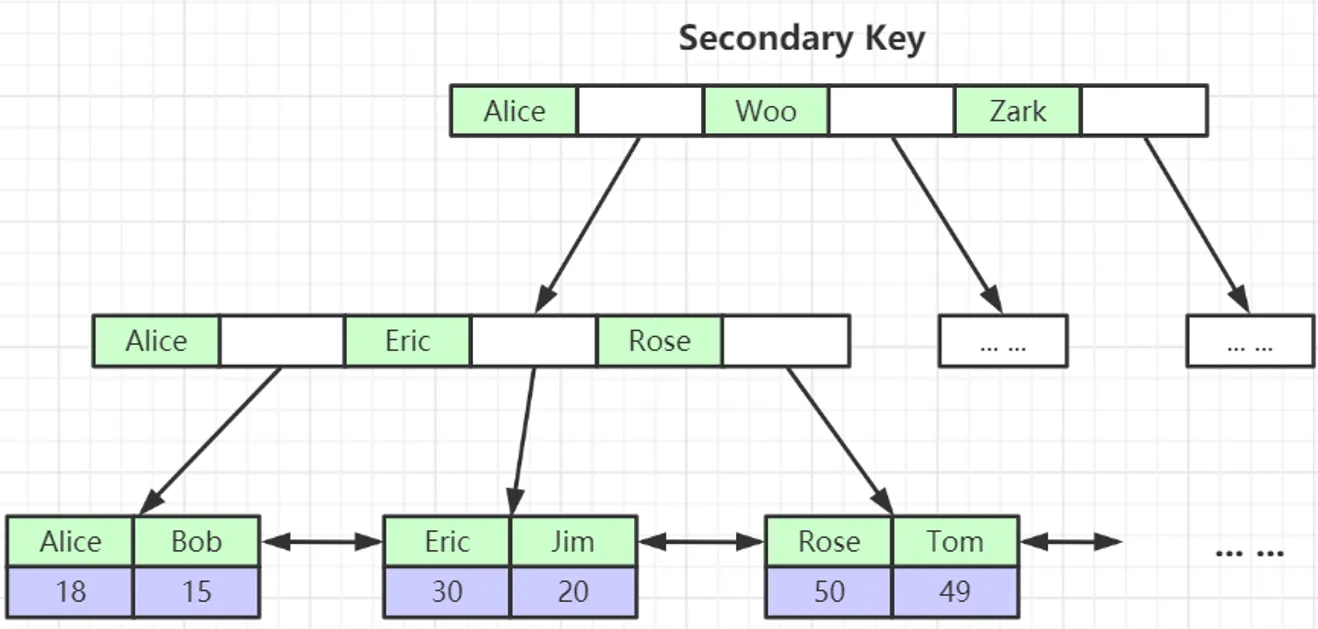
3、Hash索引
对索引的key进行一次hash计算就可以定位出数据存储的位置
很多时候Hash索引要比B+ 树索引更高效
仅能满足 “=”,“IN”,不支持范围查询
hash冲突问题
索引结构如下:(以上面MyISAM图的col3为例)
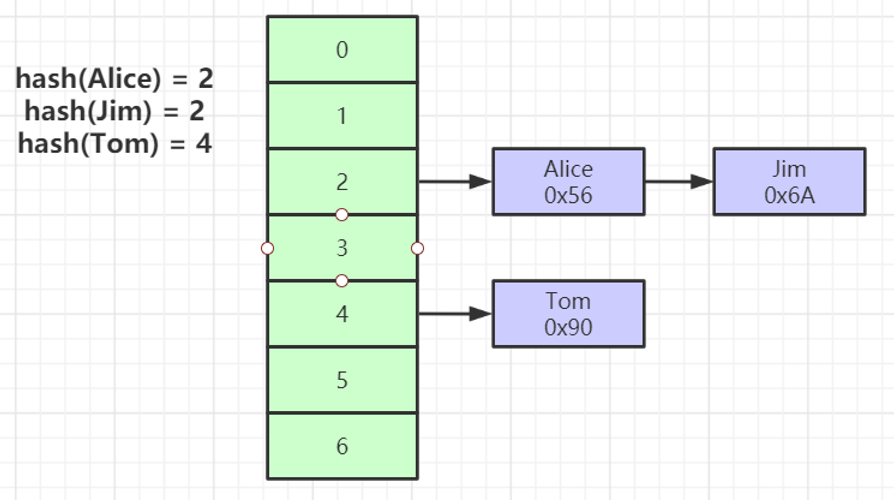
查找数据的过程就是将值根据hash算法定位到数组的索引,然后去链表中遍历。每个元素存储了数据和磁盘地址。
虽然在某些情况中,Hash索引可能比BTree索引快,但是工作中很少使用。
B+树能很好支持范围查找?
是可以的,特别注意的是有序性以及叶子节点之间的双向指针(而B树因为没有双向指针所以对范围查找不友好)。当然如果范围查询出的数据量大,速度也是慢的。
4、联合索引的底层存储结构长什么样?
联合索引:简单来说就是多个字段共同组织的一个索引。
实际工作中,一张表是不建议你建太多的单值索引。一般DBA会想办法让2~3个联合索引把80%~90%的查询条件都覆盖到位(关于索引的设计后面再学习)。
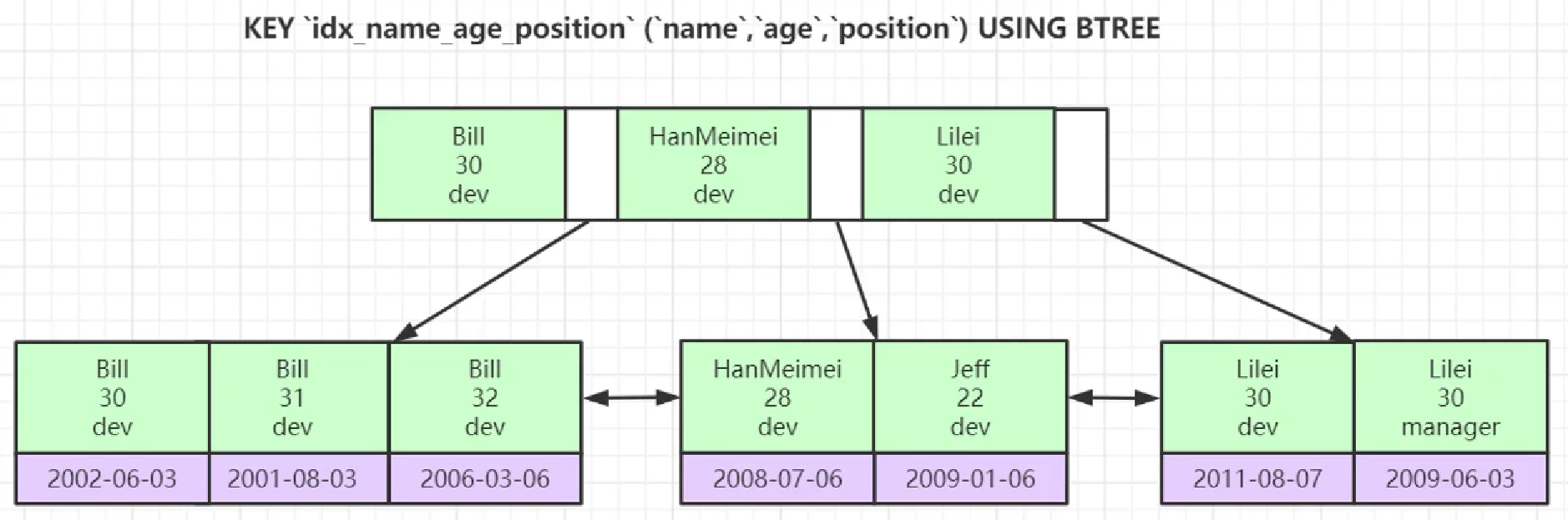
联合索引也是一种排好序的数据结构!
会按索引列的顺序维护。但是上图是联合主键,叶子节点是其他列的数据,也就是索引中的三个字段不可能都完全相同。但是辅助索引的三个字段就可能完全相同,但是存储的data(主键)是不同的,可以根据主键再回表查找。
下面哪个sql会走索引?(MySQL5.7版本中)
EXPLAIN SELECT * FROM employees WHERE name = 'Bill' and age = 31;
EXPLAIN SELECT * FROM employees WHERE age = 30 AND position = 'dev';
EXPLAIN SELECT * FROM employees WHERE position = 'manager';肯定是第一个sql句,最左前缀原理。
5、MySQL8版本的变化
课程中联合索引案例使用的脚本
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());
EXPLAIN SELECT * FROM employees WHERE name = 'Bill' and age = 31;
EXPLAIN SELECT * FROM employees WHERE age = 30 AND position = 'dev';
EXPLAIN SELECT * FROM employees WHERE position = 'manager';关于最左前缀的补充
MySQL一定是遵循最左前缀匹配的,这句话在mysql8以前是正确的,没有任何毛病。但是在MySQL 8.0中,就不一定了。
索引跳跃扫描(Index Skip Scan)
参考:https://dev.mysql.com/doc/refman/8.0/en/range-optimization.html#range-access-skip-scan
官网示例
CREATE TABLE t1 (f1 INT NOT NULL, f2 INT NOT NULL, PRIMARY KEY(f1, f2));
INSERT INTO t1 VALUES
(1,1), (1,2), (1,3), (1,4), (1,5),
(2,1), (2,2), (2,3), (2,4), (2,5);
INSERT INTO t1 SELECT f1, f2 + 5 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 10 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 20 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 40 FROM t1;
ANALYZE TABLE t1;
EXPLAIN SELECT f1, f2 FROM t1 WHERE f2 > 40;
虽然我们的SQL中,没有遵循最左前缀原则,只使用了f2作为查询条件,但是经过MySQL 8.0的优化以后,还是通过索引跳跃扫描的方式用到了索引了。
索引跳跃扫描优化原理
mysql8.013后通过优化器帮我们加了联合索引,SQL执行过程如下:
获取 f1 字段第一个唯一值,也就是 f1 = 1
构造 f1 = 1 and f2 > 40,进行范围查询
获取 f1 字段第二个唯一值,也就是 f1 = 2
构造 f1 = 2 and f2 > 40,进行范围查询
SELECT f1, f2 FROM t1 WHERE f2 > 40;
执行的最终SQL:
SELECT f1, f2 FROM t1 WHERE f1 =1 and f2 > 40
UNION
SELECT f1, f2 FROM t1 WHERE f1 =2 and f2 > 40;所以对于f1值很少,区分度不高的情况索引跳跃扫描会快一些;反之查询效率慢些。
我们不能依赖这个优化,建立索引的时候,还是优先把区分度高的,查询频繁的字段放到联合索引的左边。
限制条件
查询必须只能依赖一张表,不能多表JOIN。
查询中不能使用 GROUP BY 或 DISTINCT 语句。
查询的字段必须是索引中的列。
组合索引形式:([A_1, …, A_k,] B_1, …, B_m, C [, D_1, …, D_n]),A,D 可以为空,但是B ,C 不能为空。
这里还是有点问题,deepseek 说跳跃扫描最多只能跳过第一列。