高级数据类型是一种编程语言中提供的用于表示复杂数据结构的数据类型。相比于基础数据类型(如整数、浮点数、布尔值等),高级数据类型可以存储和操作更多的数据,并且具备更丰富的功能和操作方法。
Python的高级数据类型主要包列表、元组、字典、集合。
1. 列表的概念
在Python中,列表(List)是一种有序、可变、可重复的数据结构,用于存储一组元素。列表是Python中最常用的数据类型之一,它可以包含任意类型的元素,例如整数、浮点数、字符串等。
gf_name_list = ["高圆圆", "范冰冰", "李嘉欣", "陈红"]
info = ["yuan", 18, False]
print(type(info)) # <class 'list'>列表的特点:
列表中的元素按照顺序进行存储和管理
元素可以是任意类型且可以不一致
元素的长度理论上没有限制
列表允许包含重复的元素
列表是可变数据类型
2. 列表的基本操作
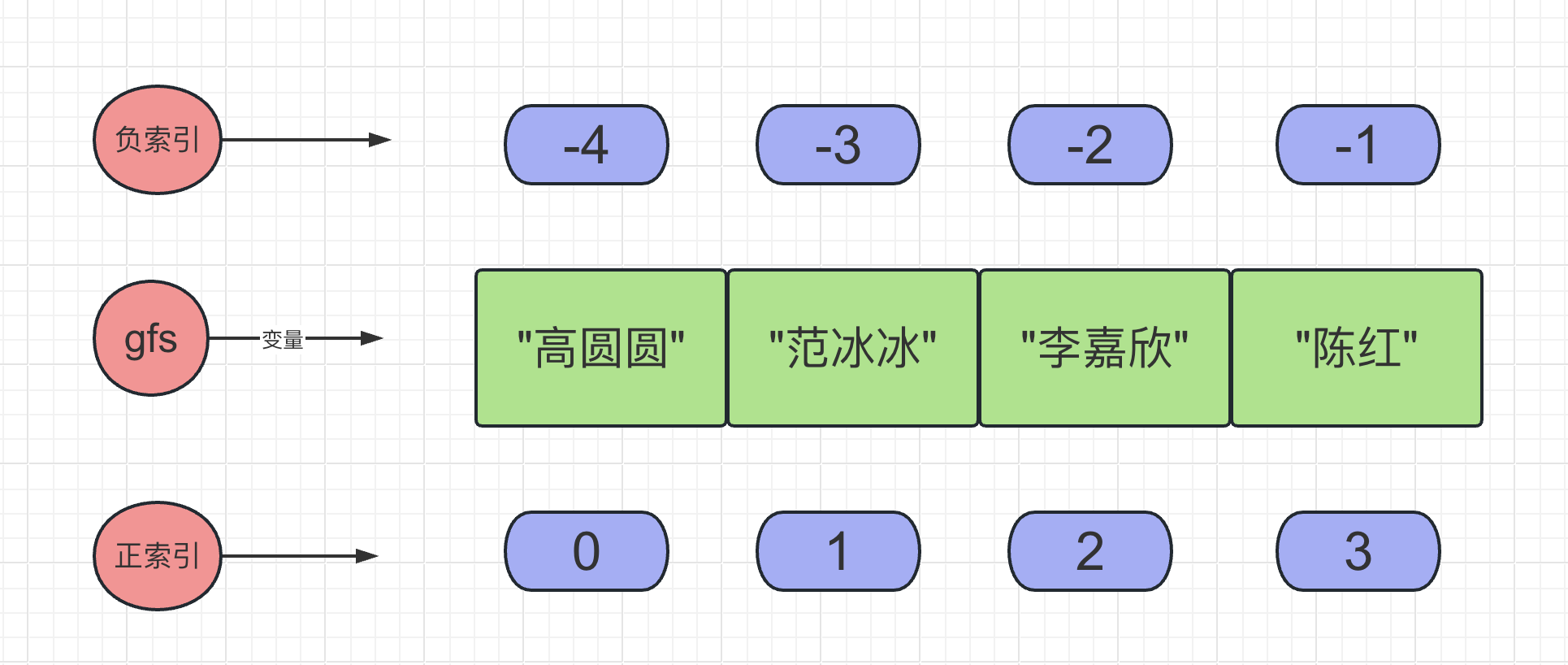
索引是管理列表的核心!
# 查询:获取的只有一个元素
l = ['高圆圆', '刘亦菲', '赵丽颖', '范冰冰', '李嘉欣']
print(l[2])
print(l[-1])
# 修改
l[3] = "佟丽娅"
# JavaScript是不支持负索引的,课程中老师说支持,这个要注意下
# 另外Python中列表和字符串索引越界会报错的,而切片不会!切片操作
# 查询操作:获取的还是一个列表
l = [10,11,12,13,14]
print(l[2:5])
print(l[-3:-1])
print(l[:3])
print(l[1:])
print(l[:])
print(l[2:4])
print(l[-3:-1])
print(l[-1:-3])
print(l[-1:-3:-1])
print(l[::2])
# 切片这里还有个思维要理解下:如果是取最后N个,就直接[-n:]就可以了
# 修改操作(这是 Python 设计上的区别:读操作返回新数据,写操作修改原数据。)
# l[1:4] = [1,2,3]
# 这样也可以,不过一般是上面那样写
# 8,8,8 是一个 元组(tuple)(因为逗号分隔的多个值默认是元组)
# Python 的切片赋值 (l[start:end] = ...) 不关心右侧是列表还是元组,只要它是可迭代对象(iterable)即可
l[1:4] = 8,8,8
print(l)1、取出的元素数量为:结束位置 - 开始位置;
2、取出元素不包含结束位置对应的索引,列表最后一个元素使用
list[-1]获取;3、当缺省开始位置时,表示从连续区域开头到结束位置;
4、当缺省结束位置时,表示从开始位置到整个连续区域末尾;
5、两者同时缺省时,与列表本身等效;
6、step为正,从左向右切,为负从右向左切。
列表是可变类型,因此索引和切片既可做查询也可以做修改!!!
这个特性带来几个灵活用法
1. 替换任意长度(不一定要长度相等)
l = [10, 11, 12, 13, 14]
l[1:3] = [1, 2, 3, 4, 5] # 替换2个元素为5个
print(l) # [10, 1, 2, 3, 4, 5, 13, 14]2. 删除一段元素
l = [10, 11, 12, 13, 14]
l[1:4] = [] # 删除索引 1~3
print(l) # [10, 14]3. 插入元素
l = [10, 14]
l[1:1] = [11, 12, 13] # 在索引1位置插入
print(l) # [10, 11, 12, 13, 14]注意事项:右边必须是可迭代对象(列表、元组、字符串等都可以)
l[1:3] = (100, 200) # ✅ 元组可以
l[2:4] = "abc" # ✅ 字符串可以,变成 ['a','b','c']
l[0:2] = 100 # ❌ 报错,整数不可迭代# 补充一个面试题目,把字符串倒数第二位变成大写
s = "hello yuan"
# 直接通过索引改会报错,字符串是不可变类型,因此通过列表中转下
lst = list(s)
lst[-2] = lst[-2].upper()
print("".join(lst))判断成员是否存在
in 关键字检查某元素是否为序列的成员
l = [10,11,12,13,14]
print(20 in l) # False
print(12 in l) # True相加
l1 = [1,2,3]
l2 = [4,5,6]
print(l1 + l2) # [1, 2, 3, 4, 5, 6]循环列表
for name in ["张三",'李四',"王五"]:
print(name)
for i in range(10): # range函数: range(start,end,step)
print(i)
# 基于for循环从100打印到1
for i in range(100,0,-1):
print(i)计算元素个数
# len函数可以计算任意容器对象的元素个数!!!
print(len("hello yuan!"))
print(len([1, 2, 3, 4, 5, 6]))
print(len(["rain", "eric", "alvin", "yuan", "Alex"]))
print(len({"k1":"v1","k2":"v2"}))3. 列表的内置方法
【1】内置方法

gf_name_list = ['高圆圆', '刘亦菲', '赵丽颖', '范冰冰', '李嘉欣']
# 一、增
# (1) 列表最后位置追加一个值
gf_name_list.append("橘梨纱")
# (2) 向列表任意位置插入一个值
gf_name_list.insert(1, "橘梨纱")
# (3) 扩展列表 这个是直接改列表,+操作是生成一个新列表
gf_name_list.extend(["橘梨纱", "波多野结衣"])
# 二、删
# (1) 按索引删除,不传索引默认删除最后一个
pop_item = gf_name_list.pop(3)
print("删除的内容:", pop_item)
print(gf_name_list)
# (2) 按元素值删除,这个无返回值
gf_name_list.remove("范冰冰")
print(gf_name_list)
# (3) 清空列表
# gf_name_list.clear()
# print(gf_name_list)
# 补充
# del 操作也可以删除,甚至可以直接删除列表对象,不过不建议用
del gf_name_list[0]
print(gf_name_list)
del gf_name_list
# 再访问gf_name_list会报错
# 三、其他操作
l = [10, 2, 34, 4, 5, 2]
# 排序(这里只是基本的自然排序,后面模块中会学习sorted可以支持自定义排序)
l.sort()
print(l)
# 翻转
l.reverse()
print(l)
# 计算某元素出现个数
print(l.count(2))
# 查看某元素的索引,不存在会报错,可以先用in判断再找,另外可以使用index和pop实现与remove类似的效果
print(l.index(34))【2】案例练习
案例1: 构建一个列表,存储1-10的偶数平方值
l = []
for i in range(1, 11):
# print(i ** 2)
# l.append(i ** 2)
if i % 2 == 0:
l.append(i ** 2)
print(l)案例2:扑克牌发牌
import random
poke_types = ['♥️', '♦️', '♠️', '♣️']
poke_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
poke_list = []
for p_type in poke_types:
for p_num in poke_nums:
# print(f"{p_type}{p_num}")
poke_list.append(f"{p_type}{p_num}")
print(poke_list)
# (1) 抽王八:每人抽一张看谁的大
# random.choice():多选一
# ret1 = random.choice(poke_list)
# print(ret1)
# ret2 = random.choice(poke_list)
# print(ret2)
# ret3 = random.choice(poke_list)
# print(ret3)
# (2) 炸金花
# random.sample :多选多
ret1 = random.sample(poke_list, 3)
print(ret1)
for i in ret1:
poke_list.remove(i)
print(len(poke_list))
ret2 = random.sample(poke_list, 3)
for i in ret2:
poke_list.remove(i)
print(len(poke_list))
ret3 = random.sample(poke_list, 3)
print(ret1)
print(ret2)
print(ret3)案例3:实现一个购物车清单,可以引导用户添加商品和删除商品
shopping_cart = []
while True:
print("--- 购物车清单 ---")
print("1. 添加商品")
print("2. 删除商品")
print("3. 查看购物车")
print("4. 结束程序")
choice = input("请输入选项:")
if choice == "1":
item = input("请输入要添加的商品:")
shopping_cart.append(item)
print("已添加商品:", item)
print()
elif choice == "2":
if len(shopping_cart) == 0:
print("购物车为空,无法删除商品。")
else:
item = input("请输入要删除的商品:")
if item in shopping_cart:
shopping_cart.remove(item)
print("已删除商品:", item)
else:
print("购物车中没有该商品。")
print()
elif choice == "3":
if len(shopping_cart) == 0:
print("购物车为空。")
else:
print("*" * 15)
print("购物车内容:")
for item in shopping_cart:
print(item)
print("*" * 15)
print()
elif choice == "4":
print("程序已结束。")
break
else:
print("无效选项,请重新输入。")
print()4. 列表的深浅拷贝(重点,笔记有修订)
【1】可变类型与不可变类型
在Python中,数据类型可以分为可变类型(Mutable)和不可变类型(Immutable)。这指的是对象在创建后是否可以更改其值或状态。
不可变类型是指创建后不能更改其值或状态的对象。如果对不可变类型的对象进行修改,将会创建一个新的对象,原始对象的值保持不变。在修改后,对象的身份标识(即内存地址)会发生变化。
以下是Python中常见的不可变类型:整数(Integer) 和浮点数(Float),布尔值(Boolean),字符串(String),元组(Tuple)
Java中的int基本类型也是不可变的,任何“修改”操作实质上是创建了新值并重新赋值给变量。
可变类型是指可以在原地修改的对象,即可以改变其值或状态。当对可变类型的对象进行修改时,不会创建新的对象,而是直接修改原始对象。在修改后,对象的身份标识(即内存地址)保持不变。
Python中常见的可变类型:列表(List),字典(Dictionary)
对于可变类型,可以通过方法调用或索引赋值进行修改,而不会改变对象的身份标识。而对于不可变类型,任何修改操作都会创建一个新的对象。
【2】可变类型的存储方式
l = [1,2,3] # 存储
print(l)
print(id(l)) # 虚拟内存地址(id返回的只是cpython层面的内存地址)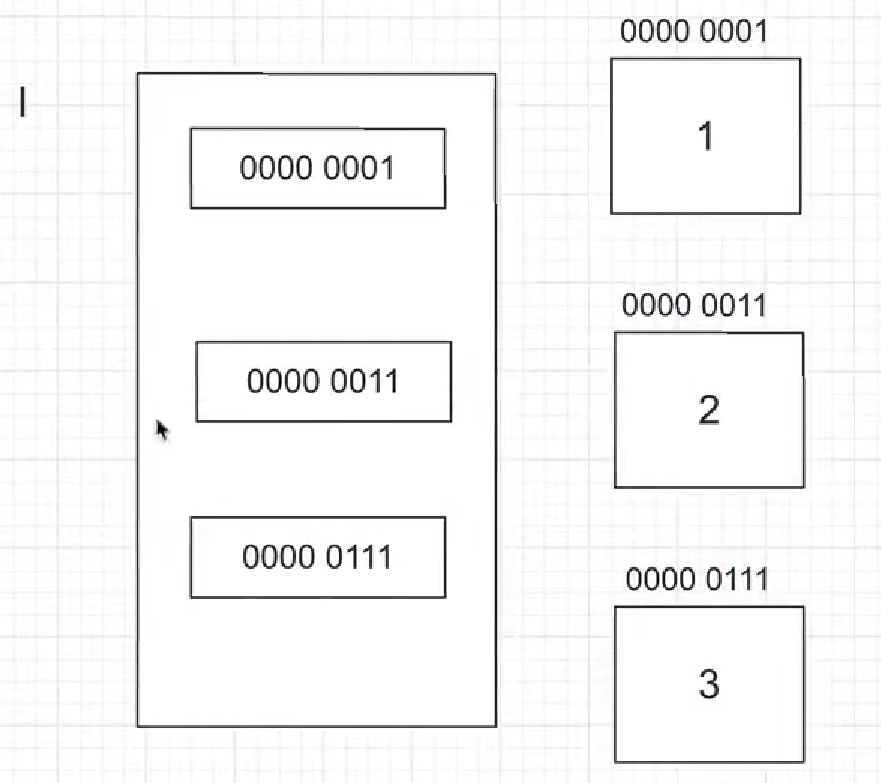
这个地方要与Java的基本数据类型的数组区分下,Python中列表存储的都是地址。
而Java中的基本类型数组是一开始就可以确定每个元素的大小,所以Java中可以直接在数组中(如int[])存储值,但是如果是List集合那还是引用,因为要装箱。
# 修改列表值,其实只是把对应索引存储的地址修改了,但是要注意的是,对于原子类型一定是新创建一个值,而不是直接在上面修改!
l[2] = 300
print(l)
print(id(l))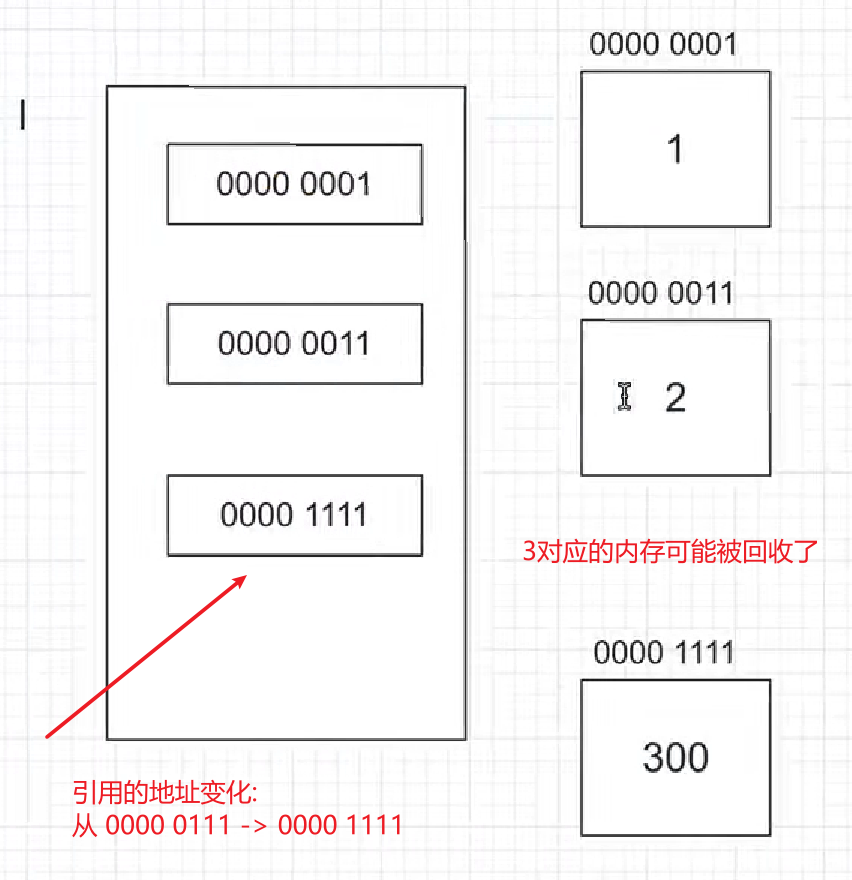
列表的可变性体现在的是它对应索引存储的内存地址可以修改,但是列表本身的内存地址并没有改变
l = [4, 5, 6] # 这个相当于创建了一个新的列表,把l重新指向了新的列表地址
print(id(l))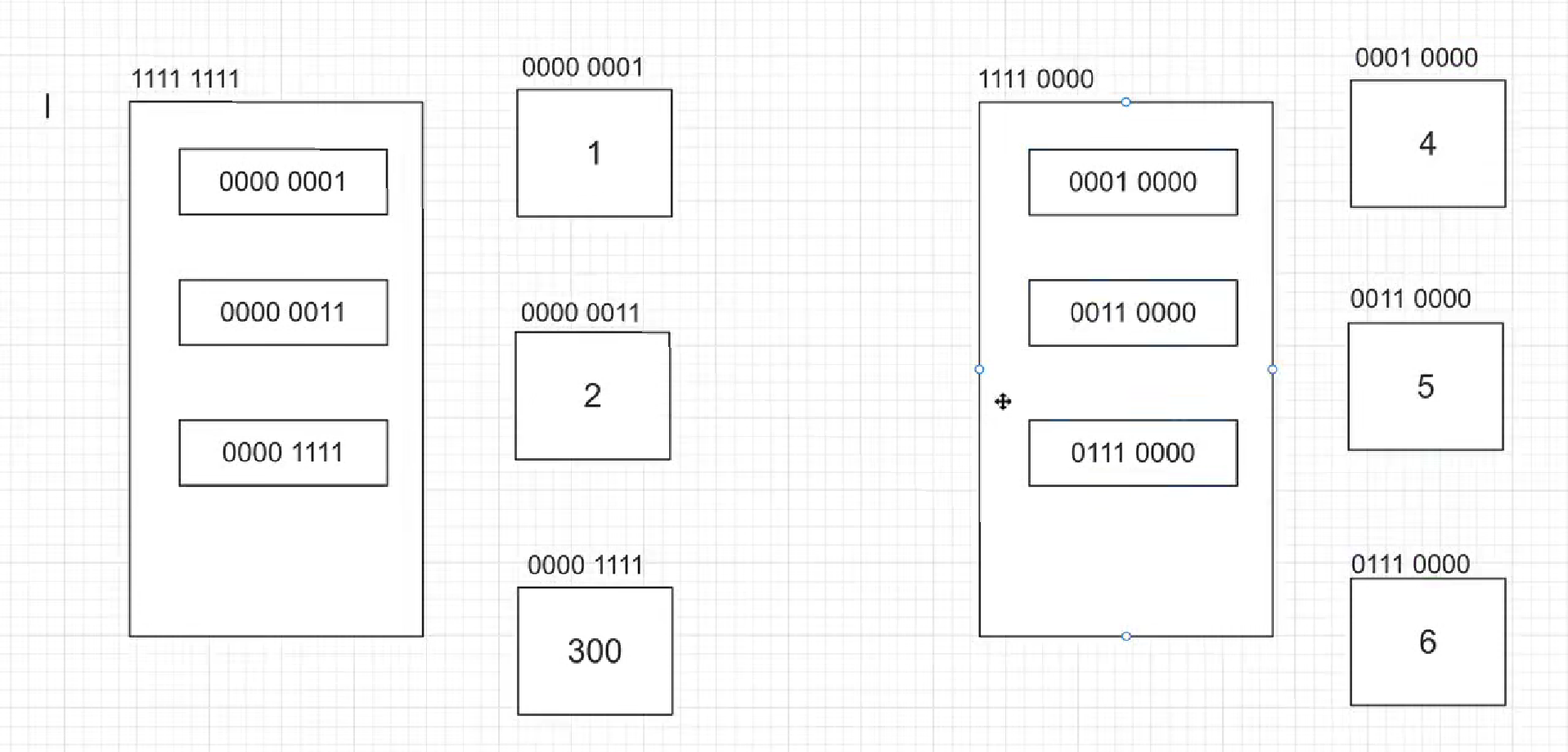
【3】可变类型的变量传递
变量实际上是对对象的引用。变量传递的核心是两个变量引用同一地址空间
# 案例1: 不可变类型的变量传递
x = 1
y = x
print(id(x))
print(id(y))
x = 2
# print(y)
print(id(x))
print(id(y))
# 案例2: 可变类型的变量传递
l1 = [1, 2, 3]
l2 = l1 # 变量传递
l1[0] = 100
print(l1, l2)
l2[1] = 200
print(l1, l2)
# 案例3:
l1 = [1, 2, 3]
l2 = [l1, 4, 5] # 也属于变量传递,相当于l2[0] = l1
l1[0] = 100
print(l1, l2)
l2[0][1] = 200
print(l1, l2)
print(id(l1), id(l2[0]))关键要弄清楚什么是变量的重新赋值,什么是对变量的修改
【4】列表的深浅拷贝
在Python中,列表的拷贝可以分为深拷贝和浅拷贝两种方式。
浅拷贝(Shallow Copy)是创建一个新的列表对象,该对象与原始列表共享相同的元素对象。当你对其中一个列表进行修改时,另一个列表也会受到影响。
你可以使用以下方法进行浅拷贝:
# (1)使用切片操作符[:]进行拷贝:
l1 = [1, 2, 3, 4, 5]
l = l1[:]
# (2)使用list()函数进行拷贝
l2 = [1, 2, 3, 4, 5]
l = list(l2)
# (3)使用copy()方法进行拷贝
l3 = [1, 2, 3, 4, 5]
l = l3.copy()
print(l)场景应用:
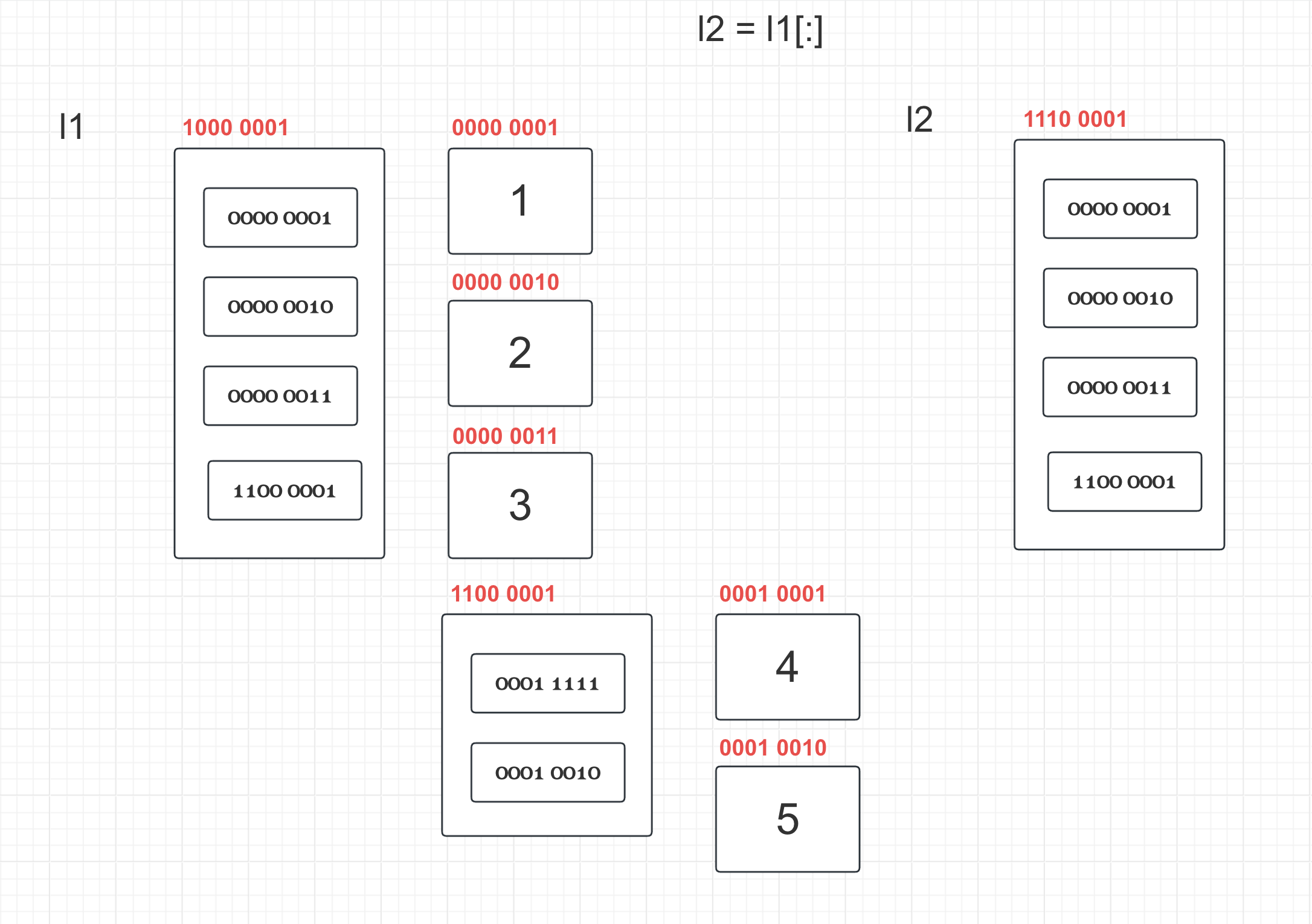
# 案例1
l1 = [1, 2, 3]
l2 = l1[:] # 浅拷贝
print(l2)
print(id(l1), id(l2))
print(id(l1[0]), id(l2[0]))
print(id(l1[1]), id(l2[1]))
print(id(l1[2]), id(l2[2]))
l1[1] = 300
print(l1, l2) # 虽然看上去互不影响,但是要看内存变化的本质,实际上还是浅拷贝
# 案例2
l = [4, 5]
l1 = [1, 2, 3, l]
l2 = l1[:]
l1[0] = 100
print(l2)
l1[3][0] = 400
print(l2)
l1[3] = 400
print(l2)深拷贝(Deep Copy)是创建一个新的列表对象,并且递归地复制原始列表中的所有元素对象。这意味着原始列表和深拷贝的列表是完全独立的,对其中一个列表的修改不会影响另一个列表。
你可以使用copy模块中的deepcopy()函数进行深拷贝:
import copy
original_list = [1, 2, 3, 4, 5]
deep_copy = copy.deepcopy(original_list)需要注意的是,深拷贝可能会更耗费内存和时间,特别是当拷贝的列表中包含大量嵌套的对象时。
5. 列表的嵌套
如果你要使用列表的嵌套来实现客户信息管理系统,可以将每个客户的信息存储在一个子列表中,然后将所有客户的子列表存储在主列表中。每个客户的信息可以按照一定的顺序存储,例如姓名、年龄、邮箱等。
目前只学习到列表,这里就用列表嵌套实现,但实际上应该是列表里面放对象,后面学完面向对象就会清楚!
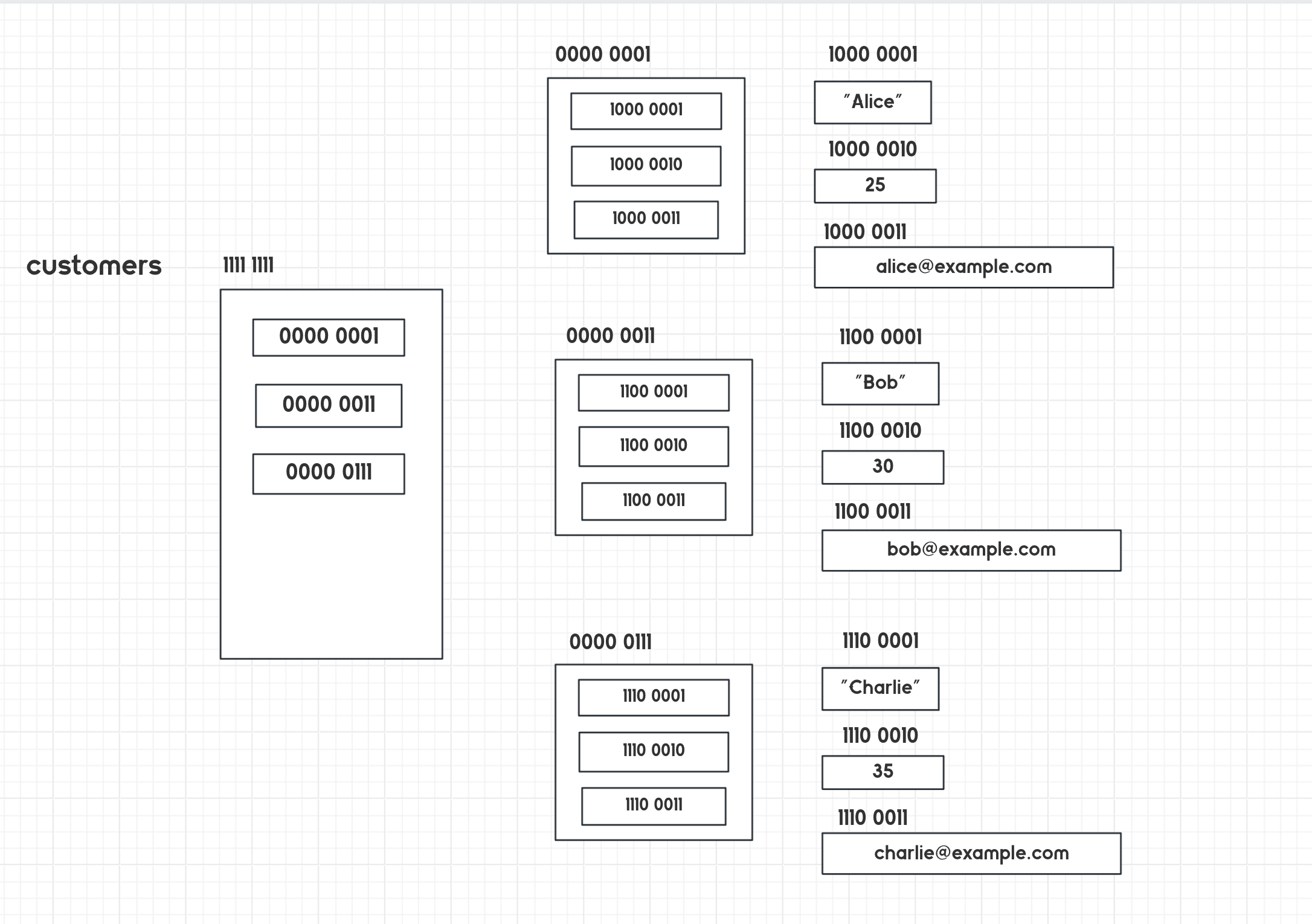
# 初始化客户信息列表
customers = [
["Alice", 25, "alice@example.com"],
["Bob", 30, "bob@example.com"],
["Charlie", 35, "charlie@example.com"]
]
# 增加客户信息
new_customer = ["David", 28, "david@example.com"]
customers.append(new_customer)
# 删除客户信息
delete_customer = "Bob"
for customer in customers:
if customer[0] == delete_customer:
customers.remove(customer)
break
# 修改客户信息
update_customer = "Alice"
for customer in customers:
if customer[0] == update_customer:
customer[1] = 26
break
# 查询客户信息
search_customer = "Charlie"
for customer in customers:
if customer[0] == search_customer:
name = customer[0]
age = customer[1]
email = customer[2]
print(f"姓名: {name}, 年龄: {age}, 邮箱: {email}")
break
# 功能整合
print("""
1. 添加客户
2. 删除客户
3. 修改客户
4. 查询一个客户
5. 查询所有客户
6. 退出
""")
# 补充一个查询全部的方法,再放入循环中添加上分支判断....在这个案例代码中,每个客户的信息被存储在一个子列表中,然后将该客户的子列表添加到客户列表中。在展示客户信息时,可以通过索引访问每个客户的具体信息。该代码使用了列表的嵌套来存储客户信息。仍然实现了添加客户信息、查看客户信息和退出程序的功能。
补充:
Python的remove是按值删除,上面的代码可以直接这样删除一个元素:customers.remove(["Bob", 30, "bob@example.com"]),而Java中不一样:
6. 列表推导式
列表推导式(List comprehensions)是一种简洁的语法,用于创建新的列表,并可以在创建过程中对元素进行转换、筛选或组合操作。
列表推导式的一般形式为:
new_list = [expression for item in iterable if condition]其中:
expression是要应用于每个元素的表达式或操作。item是来自可迭代对象(如列表、元组或字符串)的每个元素。iterable是可迭代对象,提供要遍历的元素。condition是一个可选的条件,用于筛选出满足条件的元素。
# 创建一个包含1到5的平方的列表
squares = [x**2 for x in range(1, 6)]
print(squares) # 输出: [1, 4, 9, 16, 25]
# 筛选出长度大于等于5的字符串
words = ["apple", "banana", "cherry", "date", "elderberry"]
filtered_words = [word for word in words if len(word) >= 5]
print(filtered_words) # 输出: ["apple", "banana", "cherry"]
# 将两个列表中的元素进行组合(列表推导式本身也是表达式,相当于整体当作一个表达式)
numbers = [1, 2, 3]
letters = ['A', 'B', 'C']
combined = [(number, letter) for number in numbers for letter in letters]
print(combined) # 输出: [(1, 'A'), (1, 'B'), (1, 'C'), (2, 'A'), (2, 'B'), (2, 'C'), (3, 'A'), (3, 'B'), (3, 'C')]7. 元组
元组(Tuple)是Python中的一种数据类型,它是一个有序的、不可变的序列。元组使用圆括号 () 来表示,其中的元素可以是任意类型,并且可以包含重复的元素。
与列表(List)不同,元组是不可变的,这意味着一旦创建,它的元素就不能被修改、删除或添加。元组适合用于存储一组不可变的数据。例如,你可以使用元组来表示一个坐标点的 x 和 y 坐标值,或者表示日期的年、月、日等。元组也被称为只读列表。
info = ("yuan", 20, 90)
# 获取长度
print(len(info))
# 索引和切片
print(info[2])
print(info[:2])
# 成员判断
print("yuan" in info)
# 拼接
print((1, 2) + (3, 4))
# 循环
for i in info:
print(i)
# 内置方法
# print(info.index(5)) # 找不到报错
print(info.count(2))8. 今日作业
1、反转列表中的元素顺序,numbers = [5, 2, 9, 1, 7, 6]
numbers = [5, 2, 9, 1, 7, 6]
print(numbers[::-1])2、给定一个列表,筛选出列表中大于等于 5 的元素,并存储在一个新的列表中。
s = [1 ,3 , 5 ,6 ,7, 3, 2, 10]
print([item for item in s if item > 5])3、l=[23,4,5,66,76,12,88,23,65],l保留所有的偶数
l=[23,4,5,66,76,12,88,23,65]
print([item for item in l if item % 2 == 0])注意不要在针对同一个列表遍历和移除,但是可以浅拷贝解决
# 下面的做法是错误的,虽然Python中for循环可以一边迭代一边删除,但是会跳过没有处理的元素;
# 另外remove是只会删除第一个,所以可能出现后面判断到删除了但是删除的是之前没有被判断的,比如下面的23
l=[23,4,5,23,76,12,88,23,65]
for i in l:
print("i--->", i)
if i % 2 != 0:
l.remove(i)
print(f"l删除了{i}, 现在的l-->{l}")
print(l)
# 但是可以这么玩
l=[23,4,5,23,76,12,88,23,65]
for i in l[:]:
print("i--->", i)
if i % 2 != 0:
l.remove(i)
print(f"l删除了{i}, 现在的l-->{l}")
print(l)
# 补充:我这里发现打印i是90,这是因为上面有for循环
for kkk in range(1):
print(kkk)
print(kkk) # for循环在全局作用域,结束后 kkk 还可以访问4、列表元素求和:编写一个程序,计算给定列表中所有元素的和,但要跳过列表中的负数,numbers = [1, 2, -3, 4, -5, 6, 7, -8, 9]
numbers = [1, 2, -3, 4, -5, 6, 7, -8, 9]
my_sum = 0
for i in numbers:
if i > 0:
my_sum += i
print(my_sum)numbers = [1, 2, -3, 4, -5, 6, 7, -8, 9]
sum([num for num in numbers if num > 0])【复习】5、编写一个程序,将列表中的所有字符串元素反转。
# 实际开发中一般不会出现混合类型的列表,这里是我自己加了点难度。
lst = ["abc", 1, "baaa", 2, 3, 4, "iaaa"]
print([s[::-1] if type(s) == "<class 'str'>" else s for s in lst]) # 为什么不行????Pycharm中提示不可比较
print([s[::-1] if type(s) == str else s for s in lst]) # 原来type内置函数返回的是类型对象,不是字符串,但是也不建议用type(s)比较
# print([s[::-1] if isinstance(s, str) else s for s in lst])6、从一个列表中移除重复的元素numbers = [1, 2, 3, 2, 4, 3, 5, 6, 5]
numbers = [1, 2, 3, 2, 4, 3, 5, 6, 5]
new_numbers = []
for i in numbers:
# if new_numbers.count(i) == 0:
if i not in new_numbers:
new_numbers.append(i)
print(new_numbers)
# 后面会学习集合
print(list(set(numbers)))7、编写一个程序,找到给定列表中的最大值和最小值。
min_value = numbers[0]
max_value = numbers[0]
for i in numbers:
if i > max_value:
max_value = i
if i < min_value:
min_value = i
print(f"最大值:{max_value},最小值: {min_value}")【复习方式二】8、将二维列表中所有元素放在一个新列表中numbers = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
numbers = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
new_numbers = []
for sub_numbers in numbers:
for i in sub_numbers:
new_numbers.append(i)
print(new_numbers)# 方式二:
numbers = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# 直接用推导式实现,理解:从左到右执行的,先遍历外层获取到的i就是一个个子列表,再遍历子列表,最后只要子列表的元素
# 当然这个要和前面的遍历两个外部的列表区别下
# 另外jupyter中默认会返回最后一行的返回值,因为列表推导式也是表达式,所以这里可以不print,也能打印列表
[j for i in numbers for j in i]9、编写一个程序,计算给定列表中所有正数元素的平均值
numbers = [1, 2, -3, 4, -5, 6, 7, -8, 9]
new_numbers = [i for i in numbers if i > 0]
ret = 0
for k in new_numbers:
ret += k
print(round(ret / len(new_numbers), 2))10、编写一个程序,找到给定列表中的所有大于平均值的元素并计算它们的总和
numbers = [1, 2, -3, 4, -5, 6, 7, -8, 9]
ret = 0
for k in numbers:
ret += k
avg = ret / len(numbers)
ret = 0
for p in numbers:
if p > avg:
ret += p
print(ret)11、给定一个嵌套列表,表示学生的成绩数据,数据结构如下:
scores = [[85, 90, 78], [76, 82, 88], [90, 92, 86], [68, 72, 80], [92, 88, 90]]请编写程序完成以下操作:
计算每个学生的平均分。
计算每科的平均分。
scores = [[85, 90, 78], [76, 82, 88], [90, 92, 86], [68, 72, 80], [92, 88, 90]]
# student_score_list
student_avg_list = []
for student_score_list in scores:
student_total_score = 0
for student_subject_score in student_score_list:
student_total_score += student_subject_score
student_avg_list.append(round(student_total_score / len(student_score_list), 2))
print(student_avg_list)
subject_avg_list = []
for i in range(len(scores[0])):
subject_total = 0
for student_score_list in scores:
subject_total += student_score_list[i]
subject_avg_list.append(round(subject_total / len(scores), 2))
print(subject_avg_list)12、引导用户输入页数(每页获取3条数据),实现对作品列表的切片获取,并进行格式化打印
# 假设您有一个作品列表
works = ["作品1", "作品2", "作品3", "作品4", "作品5", "作品6", "作品7", "作品8", "作品9", "作品10","作品11","作品12","作品13"]
# 用户输入1则获取:["作品1", "作品2", "作品3"] page=1 [0:3]
# 用户输入2则获取:["作品4", "作品5", "作品6"] page=2 [3:6]
# 用户输入3则获取:["作品7", "作品8", "作品9"] page=3 [6:9]
# 用户输入4则获取:["作品10", "作品11", "作品12"] page=4 [9:12]page = int(input("请输入页码"))
works = ["作品1", "作品2", "作品3", "作品4", "作品5", "作品6", "作品7", "作品8", "作品9", "作品10","作品11","作品12","作品13"]
# 错误语法,python中没有三目运算
# total_page = works % 3 == 0 ? len(works) // 3 : len(works) // 3 + 1
total_page = len(works) // 3 if len(works) % 3 == 0 else len(works) // 3 + 1
print(works[(page - 1) * 3: page * 3])
# 课堂做法
works = ["作品1", "作品2", "作品3", "作品4", "作品5", "作品6", "作品7", "作品8", "作品9", "作品10","作品11","作品12","作品13"]
page_size = 3
a, b = divmod(len(works), 3)
total_page = a + b
while True:
page = int(input("请输入查询的页数: "))
if page > total_page:
print("已超过最大页数")
continue
else:
start_index = (page - 1) * page_size
# end_index = start_index + page_size
end_index =page * page_size
print(works[start_index:end_index])
break【不会,多练!】13、实现一个简单的 ToDo List(待办事项列表)功能,实现添加,删除,置顶和完成的代办事项。
todo_list = []
while True:
print("========== ToDo List ==========")
print("1. 添加代办事项")
print("2. 删除代办事项")
print("3. 置顶代办事项")
print("4. 完成代办事项")
print("5. 退出")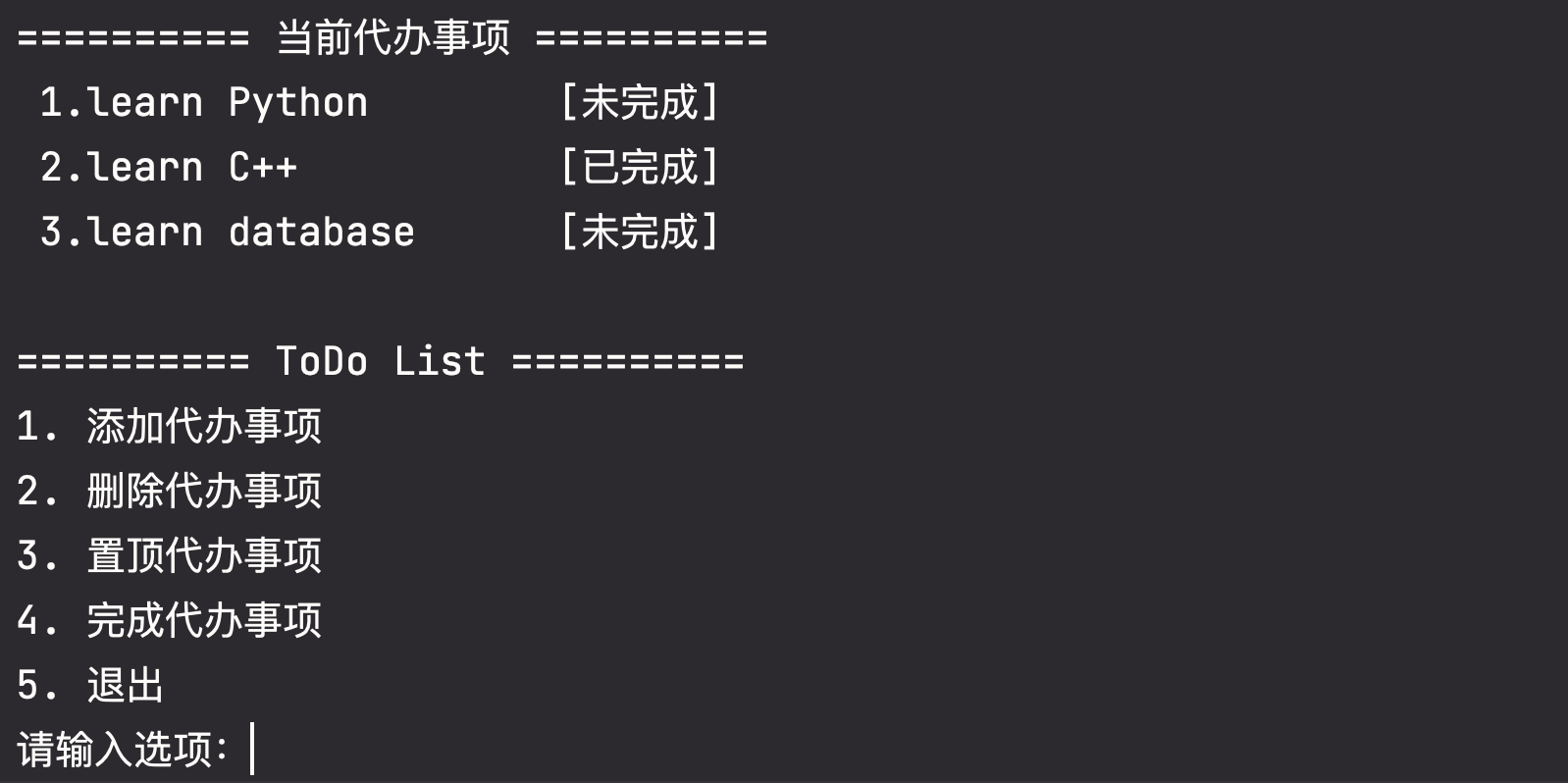
todo_list = [
['Python', '未完成'],
['C++', '已完成'],
['database', '未完成']
]
while True:
print("================当前待办事项==============")
for i in range(len(todo_list)):
print(f"{i+1}.learn {todo_list[i][0]:10}\t\t{todo_list[i][1]}")
print("========== ToDo List ==========")
print("1. 添加代办事项")
print("2. 删除代办事项")
print("3. 置顶代办事项")
print("4. 完成代办事项")
print("5. 退出")
choice = input("请输入选项:")
if choice == "1":
todo = input("请输入要添加的代办事项:")
if todo not in todo_list:
todo_list.append([todo, '未完成'])
else:
print("代办事项已存在!")
if choice == "2":
if len(todo_list) == 0:
print("列表为空,无需删除!")
continue
index = int(input("请输入要删除的代办事项序号:"))
if 1 <= index <= len(todo_list):
todo_list.pop(index - 1)
if choice == "3":
index = int(input("请输入要置顶的代办事项序号:"))
item = todo_list.pop(index - 1)
todo_list.insert(0, item)
if choice == "4":
index = int(input("请输入要完成的代办事项序号:"))
todo_list[index - 1][1] = '已完成'
if choice == "5":
print("退出程序!")
break# 课堂实现
todo_list = [
# ['Python', False]
]
print("========== ToDo List ==========")
print("1. 添加代办事项")
print("2. 删除代办事项")
print("3. 置顶代办事项")
print("4. 完成代办事项")
print("5. 退出")
while True:
choice = input("请输入您的选项")
if choice == "1":
title = input("请输入待办事项")
todo_list.append([title, False])
print(f"{todo}添加成功!")
elif choice == "2":
if todo_list:
num = int(input("请输入要删除的待办事项的序号"))
index = num - 1
if 0 <= index < len(todo_list):
del_item = todo_list.pop(index)
print(f"{del_item[0]}删除成功!")
else:
print("序号不存在!")
else:
print("目前没有待办事项!")
elif choice == "3":
if len(todo_list) < 2:
print("没有满足的待办事项置顶")
else:
num = int(input("请输入要置顶的待办事项的序号"))
index = num - 1
if 0 <= index < len(todo_list):
up_item = todo_list.pop(index)
todo_list.insert(0, up_item)
print(f"{up_item[0]}置顶成功!")
else:
print("序号不存在!")
elif choice == "4":
if len(todo_list) < 2:
print("没有满足的待办事项置顶")
else:
num = int(input("请输入要完成的待办事项的序号"))
index = num - 1
if 0 <= index < len(todo_list):
todo_list[index][1] = True
print(f"{todo_list[index][0]}已完成!")
else:
print("序号不存在!")
elif choice == "5":
print("退出程序!")
break
else:
print("非法输入")
print("================当前待办事项==============")
# enumerate学习下,方便迭代生成序号!
for i,todo in enumerate(todo_list, 1):
state = '已完成' if todo[1] else '未完成'
print(f"{i}. {todo[0]:10}\t\t{state}")